Introducción a las Redes Neuronales Artificiales - Parte 3
La ciencia de datos ha avanzado exponencialmente durante las últimas décadas, especialmente la Inteligencia Artificial. Por otra parte, la simplicidad de nuevos lenguajes computacionales, como Python, hicieron posible que usuarios con nociones básicas de programación, tuvieran acceso a la utilización de las Redes Neuronales Artificiales (RNA).
Bienvenidas/os!!, muchas gracias por visitarnos, si están comenzando en Python y este es el primer artículo al que entran en nuestro sitio, les recomendamos visitar Primeros Pasos.
En el artículo Introducción a las Redes Neuronales Artificiales (RNA) - Parte 2, discutimos como se lleva a cabo la primera fase del algoritmo Backpropagation de una RNA, llamada forward propagation, o propagación hacia adelante.
En este artículo, nos ocuparemos de la otra fase, donde reside lo verdaderamente bello de todo el proceso. Esta fase es denominada propagación hacia atrás, o backward propagation.
BACKPROPAGATION
Backpropagation es un algoritmo de aprendizaje supervisado utilizado para entrenar redes neuronales. Dado que es un método de cálculo del gradiente, el algoritmo generalmente se puede usar en otros tipos de redes neuronales artificiales.
Backpropagation se lleva a cabo en 2 fases, las cuales van repitiéndose una detrás de la otra:
- Forward propagation: Durante esta primera fase, el patrón de entrada es presentado a la red y propagado a través de las neuronas hasta llegar a la capa de salida.
- Backward propagation: Obtenidos los valores de salida de la red, se inicia la segunda fase, comparándose estos valores con la salida esperada para obtener el error. Se ajustan los pesos de la última capa proporcionalmente al error. Se pasa a la capa anterior con una retropropagación del error, ajustando los pesos y continuando con este proceso hasta llegar a la primera capa. De esta manera se van modificado los pesos de las conexiones de la red para cada patrón de aprendizaje del problema, del que conocíamos su valor de entrada y la salida deseada que debería generar la red ante dicho patrón.
FORWARD PROPAGATION
Primera fase del algoritmo backpropagation, durante la cual el patrón de entrada es presentado a la red y propagado a través de las neuronas hasta llegar a la capa de salida.
Para ver en detalle este proceso, pueden visitar el artículo Introducción a las Redes Neuronales Artificiales (RNA) - Parte 2.
BACKWARD PROPAGATION
FUNCIÓN DE PÉRDIDA (LOSS FUNCTION) Y FUNCION DE COSTO (COST FUNCTION)
Es habitual que estos 2 términos, (loss function y cost function), se utilicen como sinónimos, pero no lo son. Vamos a tratar de diferenciarlos para una mejor comprensión.
El resultado obtenido en el proceso forward propagation, es una predicción hecha por el modelo, la cual va a ser comparada con el valor real, o label, y así cuantificar cuán alejado está el modelo en su predicción. Esa diferencia, o error, va a ser calculado mediante una loss function para cada una de las muestras durante el entrenamiento.
El valor promedio de todas las loss functions del modelo es lo que se conoce como cost function.
Entonces, al medir el error promedio total de toda la red, la función de costo es la técnica que nos permite evaluar el desempeño de nuestro algoritmo/modelo.
A medida que ajustamos nuestro modelo para mejorar las predicciones, la función de costo actúa como un indicador de cómo ha mejorado dicho modelo. Esto es esencialmente un problema de optimización. Las estrategias de optimización siempre apuntan a “minimizar la función de costo”.
Dicho esto, vamos a enumerar algunas loss functions utilizadas tanto en modelos de regresión, como de clasificación, (disponibles en la API Keras):
LOSS FUNCTIONS (Regression)
- Mean Squared Error (MSE)
- Mean Absolute Error (MAE)
- Huber
- Log-Cosh
- Mean Absolute Percentage Error (MAPE) o Mean Absolute Percentage Deviation (MAPD)
- Mean Squared Logarithmic Error (MSLE)
- Cosine Similarity
LOSS FUNCTIONS (Categorical)
- Binary Cross-entropy
- Categorical Cross-entropy
- Sparse Categorical Cross-entropy
- Poisson
- Kullback–Leibler Divergence
LOSS FUNCTIONS (Hinge losses for “maximum-margin” classification)
- Hinge
- Squared Hinge
- Categorical Hinge
RETROPROPAGACIÓN DEL ERROR
Una vez obtenido el error entre el valor predicho y el valor real mediante la función de costo, se ajustan los pesos de la última capa proporcionalmente a dicho error. Se pasa a la capa anterior con una retropropagación del error, ajustando los pesos según la contribución relativa de la neurona al resultado final, y continuando con este proceso hasta llegar a la primera capa. De esta manera se van modificado los pesos de las conexiones de la red para cada patrón de aprendizaje del problema, del cual conocíamos su valor de entrada y la salida real que debería generar la red.
Backward propagation es un mecanismo utilizado en aprendizaje supervisado de redes neuronales artificiales, el cual utiliza el algoritmo descenso de gradiente o gradient descent durante la retropropagación del error.
GRADIENT DESCENT
El descenso de gradiente es un algoritmo de optimización que me permite hallar el valor mínimo de una función, mediante la búsqueda de los valores óptimos de parámetros de dicha función.
En el caso de RNA, gradient descent se utiliza para encontrar los valores óptimos de los pesos (w) que me disminuyan al mínimo los valores de mi cost function (C), y así reducir el error entre los valores predichos y los valores reales o labels.
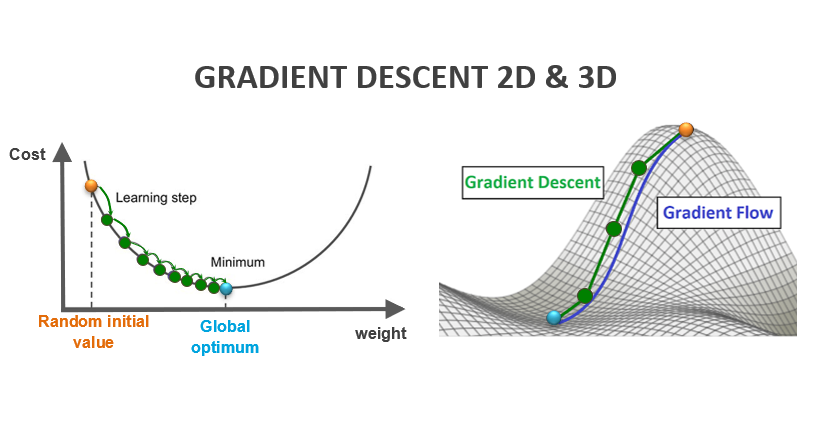
Figura 1: Gradient Descent en 2D (Fuente: es.quish.tv) y 3D (Fuente: offconvex.org)
LEARNING RATE (STEP SIZE)
En aprendizaje automático, learning rate, o tasa de aprendizaje, es un hiperparámetro de ajuste de un algoritmo de optimización, gradient descent en este caso, que determina el step size en cada iteración mientras avanza hacia el valor mínimo de una loss function.
Para lograr una rápida y eficaz convergencia hacia el valor mínimo, es muy importante utilizar un learning rate apropiado, el cual puede ser fijo, o variable.
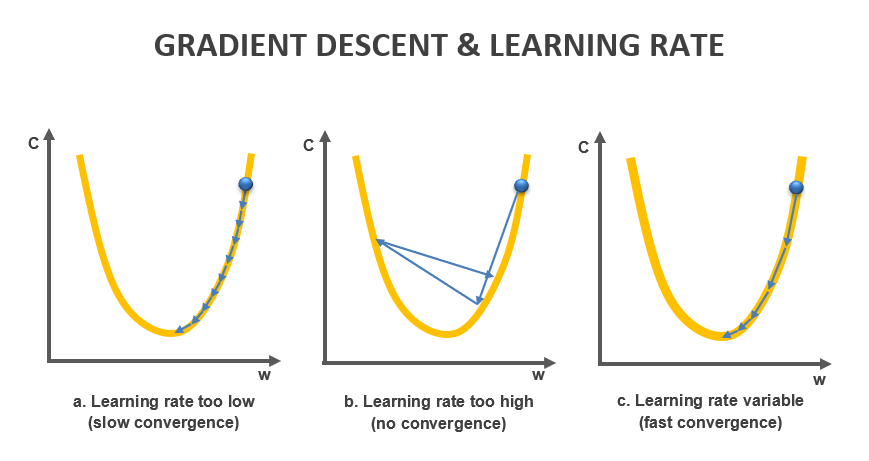
Figura 2: Respuestas del Gradient Descent utilizando diferentes learning rates
Si el Learning rate es demasiado pequeño, corremos el riesgo de que el modelo no sea capaz de converger en un período de tiempo razonable, o converger hacia un mínimo local (Figura 2a). En cambio, si es muy alto, podríamos no encontrar el valor mínimo, y así generar que el modelo no pueda converger nunca (Figura 2b). En general, el valor del learning rate durante el entrenamiento es variable, empieza con valores altos, los cuales van disminuyendo según avance el entrenamiento (Figura 2c).
Para encontrar los valores más adecuados de learning rate en un modelo, se utilizan algoritmos de optimización, o simplemente, optimizadores.
Optimizadores de learning rate (Fuente: Keras API reference / Optimizers)
- SGD (Stochastic Gradient Descent)
- Adam (Adaptive moment estimation)
- RMSP (Root Mean Square Propagation)
- Adadelta
- Adagrad
- Adamax
- Nadam
- Ftrl
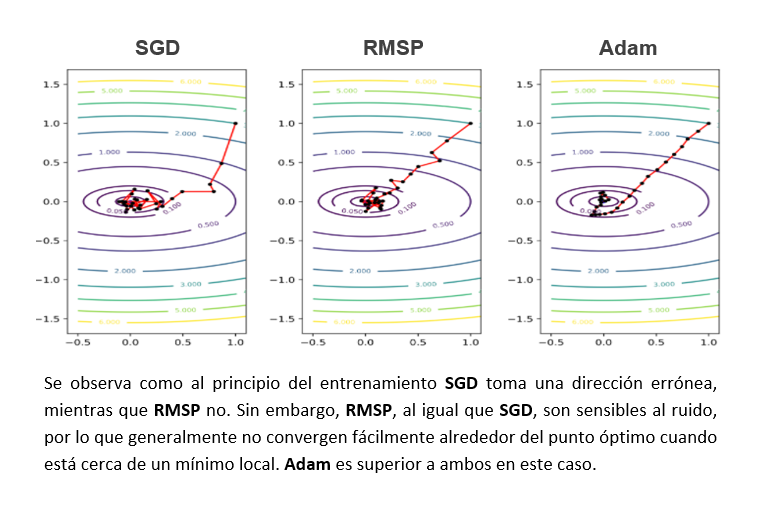
Figura 3: Comparación entre los optimizadores Adam, SGD y RMSP (Fuente: atcold.github.io/pytorch-Deep-Learning)
VANISHING GRADIENTS (DESVANECIMIENTO DE GRADIENTES)
Como hemos mencionado, el algoritmo gradient descent es el encargado de minimizar la función de costo modificando los pesos durante la fase backward propagation. Para ello, durante la retropropagación, distribuye el error total de la red asignándole una porción de dicho error a cada neurona según la contribución relativa de la neurona. Esta contribución relativa de cada neurona aumenta al ir acercándose a las últimas capas.
A medida que crece el número de capas o layers de una red neuronal, las primeras capas, (las más cercanos a la input layer), se verán menos afectadas por el cálculo del error a medida que vamos yendo backward por la red neuronal. Esto es porque cada uno de los pesos de la red neuronal recibe una actualización proporcional a la derivada parcial de la función de error con respecto al peso actual en cada iteración de entrenamiento. (y los pesos en los nodos de las primeras capas tienen muy poca injerencia en el resultado final, por eso casi no van a corregirse durante la backward propagation).
Entonces, los gradientes se van a ir haciendo cada vez más pequeños hacia las primeras capas de la red, hasta casi hacerse 0 y desaparecer, de ahí el término Vanishing Gradients. Esto generará que las neuronas de las primeras capas no modifiquen casi nada el valor de sus pesos, y así sean incapaces de entrenarse, entorpeciendo, y hasta en algunos casos, deteniendo el avance del aprendizaje de la red.
Para tratar de mitigar este fenómeno, hay varios métodos, tales como:
- Función de activación: (La función sigmoide y tanh, son susceptibles a provocar el desvanecimiento de gradiente. ReLU, en cambio, reduce en gran medida este fenómeno)
- Inicialización de pesos: Proceso que nos permite elegir aleatoriamente el valor de los pesos al comienzo del entrenamiento, en el caso del iniciador de pesos Xavier, los pesos provienen de valores aleatorios con probabilidad de distribución uniforme (Xavier es utilizado cuando la función de activación es la función logística o la función tanh). He es otro inicializador de pesos, del cual los pesos vienen de valores aleatorios con probabilidad de distribución normal o gaussiana (Se utiliza con la función de activación ReLU).
- Normalización: el método Batch Normalization, además de contrarrestar el efecto del desvanecimiento de gradientes, es un método que le da rapidez y estabilidad al entrenamiento de la red.
Si desean más información sobre Inicialización de Pesos, pueden entrar AQUÍ. Por otro lado, si están interesados en Normalización, pueden ingresar AQUÍ.
BATCH SIZE
Si las Redes Neuronales son muy grandes, resolver todos los parámetros del algoritmo gradient descent al mismo tiempo es una tarea que puede llevar mucho tiempo, o hasta quizás se torne imposible computacionalmente. Debido a esto, podemos definir una cantidad de muestras, o samples, para que el programa solamente procese dicha cantidad por vez durante el entrenamiento de la red. A este número de samples lo denominamos batch.
Batch size es un hiperparámetro de ajuste. A continuación, describiremos brevemente cómo trabaja batch size.
Por ejemplo, si tengo 1030 samples y le doy batch_size=100, entonces el programa elige al azar 100 samples y entrena el modelo, luego toma aleatoriamente 100 samples más, y vuelve a reentrenar el modelo utilizando el modelo anterior + las nuevas 100 muestras. Cuando tiene el modelo nuevo, toma otras 100 samples al azar, y así sucesivamente. En este caso, cuando llegue a 1000, solo le van a quedar 30 samples. Al final, al utilizar batch_size=100 en este modelo, voy a generar 11 batches (10 batches de 100 samples, y 1 batch de 30 samples).
Notemos que el último batch va a ser sólo de 30 samples, número diferente y mucho menor a la cantidad de muestras que venía procesando por vez. Esto, tomar pocas muestras en cada batch, puede darnos resultados irreales y, por ende, deberíamos tenerlo en cuenta a la hora de definir dicho valor.
- Batch Gradient Descent: el total de las muestras de la red son procesadas al mismo tiempo para obtener el gradiente.
- Mini-batch Gradient Descent: computa el gradiente tomando un número de muestras definido por el valor batch size. Cada conjunto de muestras es llamado mini-batch. Es más preciso en cuanto a encontrar el mínimo que el Stochastic GD pero, sin embargo, es muy susceptible a los mínimos locales.
- Stochastic Gradient Descent: (Batch size = 1). SGD toma 1 muestra al azar y entrena la red. Luego toma otra aleatoriamente, y reentrena el modelo obtenido con la primera muestra, utilizando la nueva muestra. Posteriormente toma una tercera muestra, y reentrena la red modelada con las primeras 2 muestras agregando la nueva muestra, y así sucesivamente. Este procesamiento es mucho más rápido que los anteriores, pero es muy inestable. Es muy poco preciso con el valor mínimo que debe obtener, es muy afectado por mínimos locales, etc.
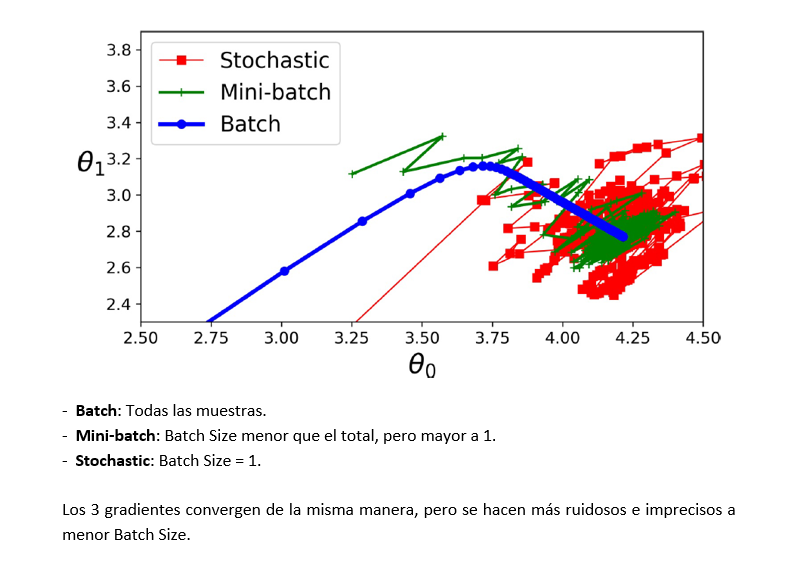
Figura 4: Comparación entre Batch, Mini-batch y Stochastic (Fuente: Aurélien Géron (2019), Hands-On Machine Learning with Scikit-Learn and TensorFlow - 2nd edition (Page 173). Editorial O’Reilly)
>
UNDERFITTING Y OVERFITTING
Para finalizar, vamos a hablar sobre estos 2 fenómenos, los cuales suelen aparecer al entrenar RNA.
UNDERFITTING
Cuando entrenamos nuestro modelo, nuestra meta principal es que funcione correctamente con los datos de entrada que le ingresamos, (por ejemplo, si es una clasificación, esperamos que pueda clasificar correctamente los datos en 2 o varias clases).
Si el modelo no puede clasificar correctamente los datos con los que fue entrenado, entonces el modelo está underfitting, o no ajustado. Podemos decir que un modelo no se ajusta bien cuando las métricas proporcionadas para los datos de entrenamiento son deficientes, lo que significa que la precisión del entrenamiento del modelo es baja y/o la loss function de entrenamiento es alta.
Si el modelo no puede clasificar los datos de entrenamiento, es probable que no prediga bien datos que no ha visto antes.
Si esto ocurre, podemos utilizar alguna de estas prácticas:
- Aumentar la complejidad del modelo
- Agregar más datos al entrenamiento (Si es posible).
- Reducir el dropout (si lo hubiera)
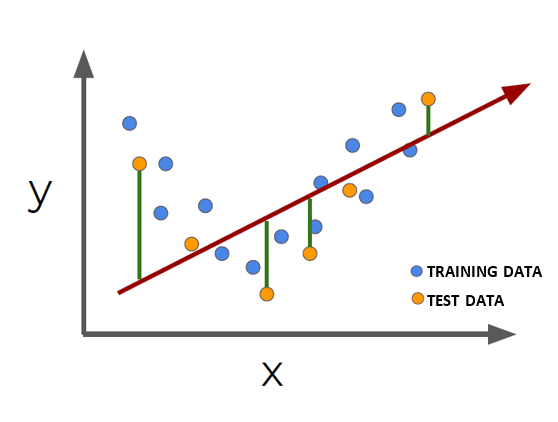
Figura 5: UNDERFITTING (Fuente: World Wide Web)
OVERFITTING
Un modelo está sobreentrenado, (overfitting), cuando el error utilizando los datos de entrenamiento es muy bajo, pero es alto cuando el modelo se aplica a datos nuevos.
En las Redes Neuronales hay cientos de parámetros y hay muchas posibilidades de caer en overfitting. Para mitigar este problema, hay varios métodos, de los cuales mencionaremos:
- Simplificación del modelo
- L1/L2 Regularization
- Dropout
- Expanding data
- Early stopping
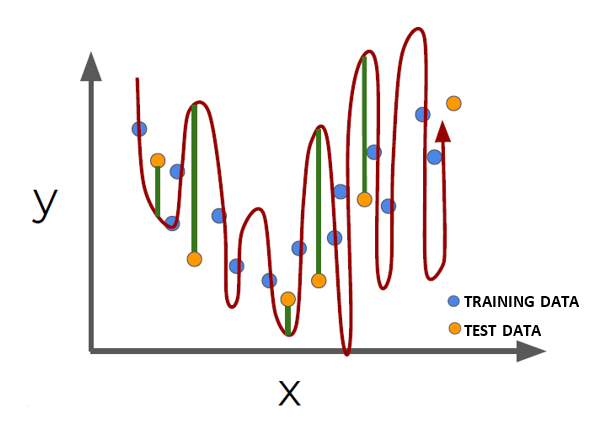
Figura 5: OVERFITTING (Fuente: World Wide Web)
Y así llegamos al final de este artículo, pero antes haremos un breve repaso del mismo.
Hemos visto cómo funciona la backward propagation, una de las partes más interesantes del entrenamiento de las redes neuronales.
También hemos visto cómo se calcula el error utilizando loss functions, y también como la cost function trabaja como indicador de mejora de un modelo. Luego hemos hablado del gradient descent, y hemos explorado parámetros y procedimientos para optimizarlo. Para finalizar, explicamos los conceptos de overfitting y underfitting, y cómo tratar de remediarlos.
Les agradecemos su tiempo y esperamos fervientemente que hayan disfrutado este artículo. Si tienen alguna consulta, desean hacer algún comentario o sugerencia para mejorar el contenido, o simplemente indicarles qué les pareció este artículo, debajo pueden hacerlo.
Esperamos reencontrarlos en algún otro artículo del sitio. Hasta luego!
Tags
Recent Posts