Introducción a las Redes Neuronales Artificiales - Parte 2
La ciencia de datos ha avanzado exponencialmente durante las últimas décadas, especialmente la Inteligencia Artificial. Por otra parte, la simplicidad de nuevos lenguajes computacionales, como Python, hicieron posible que usuarios con nociones básicas de programación, tuvieran acceso a la utilización de las Redes Neuronales Artificiales (RNA).
Bienvenidas/os!!, muchas gracias por visitarnos, si están comenzando en Python y este es el primer artículo al que entran en nuestro sitio, les recomendamos visitar Primeros Pasos.
En este artículo, discutiremos la propagación hacia adelante, o forward propagation de una red, que consiste en el proceso por el cual la neurona artificial de una red neuronal artificial (RNA), recibe los datos de entrada, hasta que devuelve una respuesta de salida o output. Repasaremos los conceptos de pesos, sesgo, función de activación, etc.
REDES NEURONALES ARTIFICIALES (RNA)
La estructura de las RNA trata de ser lo más similar posible a la estructura del cerebro humano. Yendo a la parte más elemental del mismo, veremos cómo tratamos de imitar el funcionamiento de una neurona mediante lo que se conoce como neurona artificial o nodo.
NEURONA ARTIFICIAL, NODO O PERCEPTRÓN
Las neuronas biológicas reciben impulsos eléctricos a través de las dendritas, los procesan en el soma (body) y luego lo envían a otra neurona por medio del axón (axon).
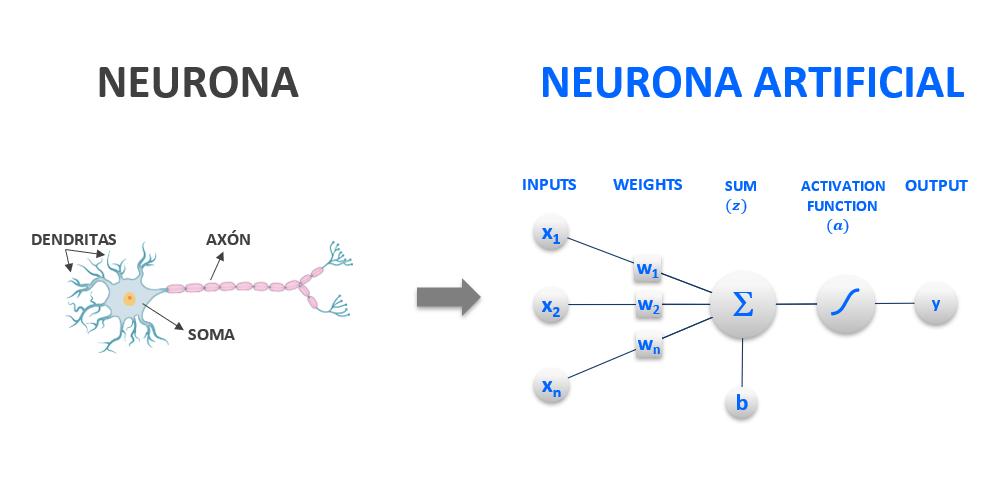
Figura 1: Neurona biológica y neurona artificial
En el caso de RNA (Redes Neuronales Artificiales) o ANN (Artificial Neural Networks), la neurona artificial, o nodo, va a emular el comportamiento de la neurona biológica mediante un modelo matemático conocido como perceptrón.
BACKPROPAGATION
Es un algoritmo de aprendizaje supervisado utilizado para entrenar redes neuronales. Dado que es un método de cálculo del gradiente, el algoritmo generalmente se puede usar en otros tipos de redes neuronales artificiales.
Backpropagation se lleva a cabo en 2 fases, las cuales van repitiéndose una detrás de la otra:
- Forward propagation: Durante esta primera fase, el patrón de entrada es presentado a la red y propagado a través de las neuronas hasta llegar a la capa de salida.
- Backward propagation: Obtenidos los valores de salida de la red, se inicia la segunda fase, comparándose estos valores con la salida esperada para obtener el error. Se ajustan los pesos de la última capa proporcionalmente al error. Se pasa a la capa anterior con una retropropagación del error, ajustando los pesos y continuando con este proceso hasta llegar a la primera capa. De esta manera se van modificado los pesos de las conexiones de la red para cada patrón de aprendizaje del problema, del que conocíamos su valor de entrada y la salida deseada que debería generar la red ante dicho patrón.
FORWARD PROPAGATION
Esta fase va a constar de 4 etapas:
- Recibir los datos de entrada.
- Calcular los pesos y multiplicarlos por los datos de entrada.
- Realizar una sumatoria de todos estos productos y adicionarle un valor (bias).
- Al resultado aplicarle una función de activación.
DATOS DE ENTRADA O INPUTS (x1,…,xn)
Son los valores que recibe la neurona. En el caso de los nodos de la capa de entrada o input layer, los valores serán suministrados por nosotros. En el caso de las neuronas de las capas ocultas y las de salida, (hidden layers, output layers), los datos de entrada recibidos provienen de otra/s neurona/s.
PESOS O WEIGHTS (w1,…,wn)**
El peso le otorga al input el impacto que necesita en la función de suma del elemento de procesamiento. Sus valores son estimados durante el entrenamiento de la red.
A cada input (w1,…,xn) , el sistema le asigna un peso o weight (w1,…,wn) durante el entrenamiento del modelo, para luego multiplicarlos entre ellos.
$$ w_1.x_1,…,w_n.x_n $$
SESGO O BIAS (b)**
Se suman todos los productos (wn.xn) y se le adiciona un valor, conocido como bias.
El bias es un valor de sesgo o “tendencioso” que controla la predisposición de la neurona a dar un resultado deseado, ya que, en términos algebraicos, el bias permite que un clasificador traslade su límite de decisión hacia la izquierda o hacia la derecha una distancia constante en una dirección específica, independientemente de los pesos.
El sesgo ayuda a entrenar el modelo más rápido y con mejor calidad.
Al resultado de esta sumatoria se lo denomina con la letra z .
$$ z= w_1.x_1,…,w_n.x_n + b $$
$$ z = \bigg(\sum_{i=1}^n w_{i}.x_{i}\bigg) + b $$
El resultado (z), va a ser juzgado en una función de activación.
FUNCIÓN DE ACTIVACIÓN O ACTIVATION FUNCTION (a)
La función de activación transmite la información generada en la suma ponderada lineal, z= ∑xn.wn + b, y la transforma como salida. Puede oficiar como filtro, umbral, etc.
$$ a = \sigma(z) $$
Si bien el uso de una función de activación introduce un paso adicional en cada capa en nuestra red neuronal aumentando su complejidad, con ella generamos una transformación NO LINEAL a los nodos, ya que, si no introdujéramos la función de activación, la red neuronal se convertiría prácticamente en un modelo de regresión lineal, incapaz de resolver situaciones complejas.
La elección de la función de activación tiene un gran impacto en la capacidad y rendimiento de la red neuronal, de hecho, es común utilizar diferentes funciones de activación en distintas partes el modelo.
Para poder utilizar una función como función de activación, hay que prestar atención a ciertas características, tales como:
- Derivabilidad: La función de activación debe ser derivable (Esto es porque las redes neuronales usualmente se entrenan utilizando el algoritmo back-propagation, y se requiere la derivada de primer orden del error de predicción para actualizar los weights del modelo).
- Rendimiento del Sistema: En una red neuronal suele haber cientos de neuronas, si a esto le sumamos que para cada una se van a recalcular función de activación, pesos, bias, etc., n veces durante el entrenamiento, nos encontraremos con millones de cálculos. Por ello, las funciones de activación deberían consumir la menor cantidad de recursos del sistema posible.
DATOS DE SALIDA O OUTPUTS El resultado de la función de activación será el dato de salida del nodo. El mismo pasará a otra/s neurona/s, o bien, si la neurona está en la capa de salida, el dato de salida de la misma ya será el valor predicho por el modelo. Este último será comparado con el dato verdadero y se calculará un error total mediante una cost function.
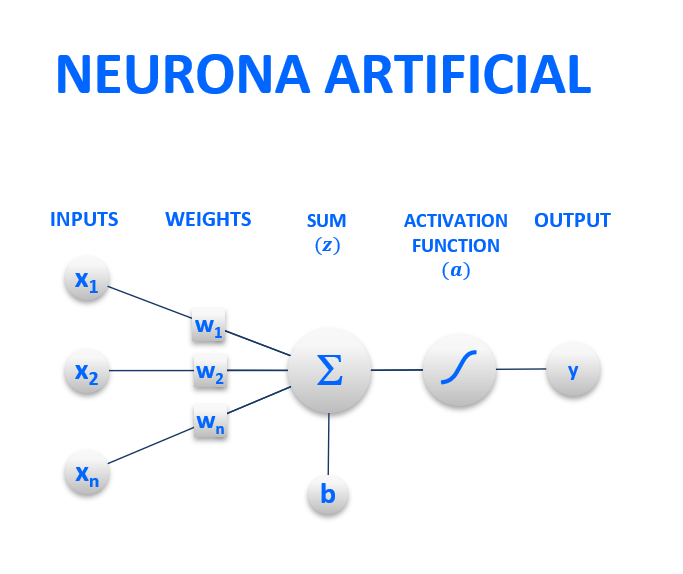
Figura 2: Neurona Artificial (inputs, pesos, sumatoria, función de activación, output)
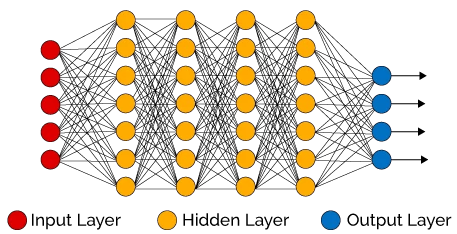
Figura 3: Red Neuronal Artificial
Si bien hay varias funciones de activación, veremos tres muy comunes en las RNA.
- FUNCIÓN LOGÍSTICA O SIGMOIDE
- FUNCIÓN TANH
- FUNCIÓN ReLU
ℹ️ Si desean más información sobre otras funciones de activación, pueden visitar este SITIO WEB .
FUNCIÓN LOGÍSTICA o SIGMOIDE
- Función con forma de S donde los valores oscilan entre 0 y 1 (centrados en 0.5).
- Cuando los inputs son pequeños o grandes, la función se concentra en 0, (para los pequeños), y en 1 (para los valores grandes), provocando una derivada cercana a 0. Esto alimenta el problema de vanishing gradients durante la back-propagation.
- Al trabajar con exponenciales, es costosa computacionalmente.
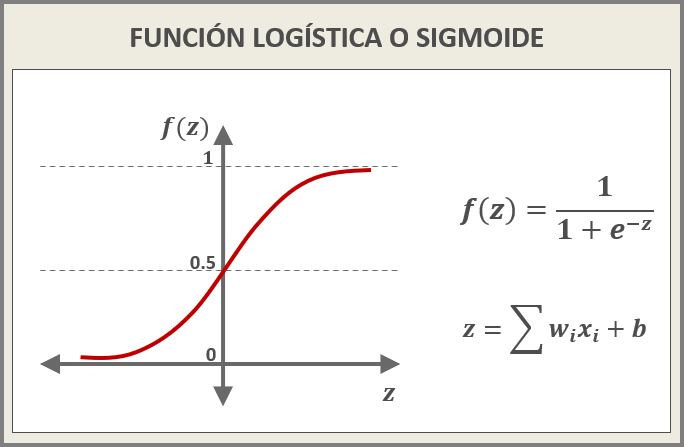
Figura 4: FUNCIÓN LOGÍSTICA
FUNCIÓN TANH (Tangente Hiperbólica)
- Al igual que la función logística, TANH tiene forma de S, pero en este caso sus valores oscilan entre -1 y 1 (centrados en 0).
- Presentan el mismo comportamiento que la función logística frente al problema de vanishing gradients durante la back-propagation.
- Al trabajar con exponenciales, es costosa computacionalmente.
- Al ser simétrica al valor 0, la función TANH suele converger más rápidamente que la función logística.
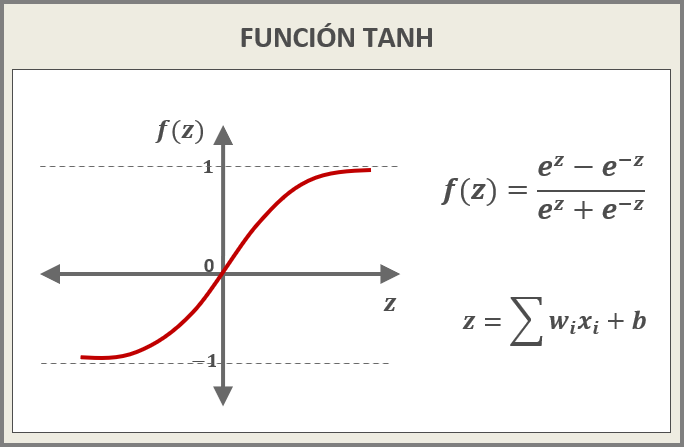
Figura 5: FUNCIÓN TANH
FUNCIÓN ReLU (Rectified Linear Unit)
- Esta función retorna el máximo valor z. En el caso de ser menor a 0, retornará 0 (máx.). Cuando los valores de z son mayores a 0, el máximo va a depender del resultado de la función z= ∑xn.wn + b.
- Tiene menos problemas con los vanishing gradients que las funciones logística y tanh.
- Al ser sus cálculos comparación, suma y producto, es económica computacionalmente.
- Tiene la desventaja de no estar centrada en 0.
- Al no tener límite superior, los valores pueden tomar valores exorbitantes e inutilizar la neurona (A este fenómeno se lo conoce como gradientes explosivos o exploding gradients).
- ReLU moribundo: Al ser siempre 0 el valor de salida para valores negativos, si una neurona modificó sus weights de tal manera que el resultado de z siempre va a ser negativo, la salida de la función ReLU siempre va a ser igual a cero. Bajo estas condiciones, ningún gradiente va a poder fluir durante la back-propagation a través de la neurona, por lo que la neurona queda atascada en un estado inactivo perpetuo y “muere”. Este fenómeno se denomina ReLU moribundo. En algunos casos, una gran cantidad de neuronas en una red pueden “morir”, disminuyendo efectivamente la capacidad del modelo. Este problema suele surgir cuando la tasa de aprendizaje, o learning rate, es demasiado alta.
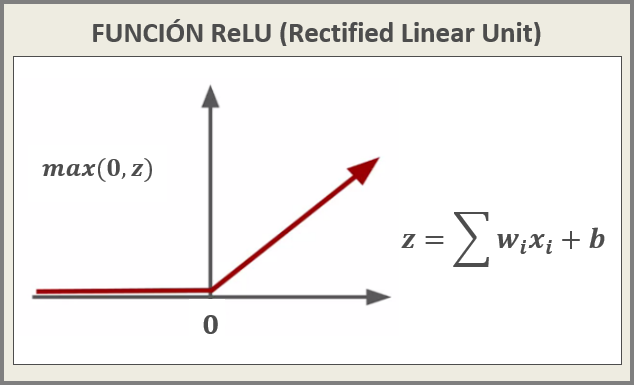
Figura 6: FUNCIÓN ReLU
En resumen, a lo largo de este artículo hemos repasado el proceso de forward propagation de una red neuronal:
- wn . xn Los datos de entrada (x) que ingresan a cada neurona son multiplicados por un valor llamado peso (w), calculado durante el entrenamiento del modelo.
- z= w1.x1,...,wn.xn + b Luego se realiza la sumatoria de todos estos productos y se le suma un valor de sesgo (b), obteniendo z.
- a= σ(z) El valor z es juzgado por una función de activación.
Por el momento vamos a detenernos aquí, dejaremos la revisión de la segunda fase del entrenamiento, backward propagation, para el artículo Introducción a las Redes Neuronales Artificiales (RNA) - Parte 3.
Les agradecemos su tiempo y esperamos fervientemente que hayan disfrutado este artículo. Si tienen alguna consulta, desean hacer algún comentario o sugerencia para mejorar el contenido, o simplemente indicarles qué les pareció este artículo, debajo pueden hacerlo.
Esperamos reencontrarlos en algún otro artículo del sitio. Hasta luego!
Tags
Recent Posts