Introducción a las Redes Neuronales Artificiales - Parte 1

La ciencia de datos ha avanzado exponencialmente durante las últimas décadas, especialmente la Inteligencia Artificial. Por otra parte, la simplicidad de nuevos lenguajes computacionales, como Python, hicieron posible que usuarios con nociones básicas de programación, tuvieran acceso a la utilización de las Redes Neuronales Artificiales (RNA).
Bienvenidas/os!!, muchas gracias por visitarnos, si están comenzando en Python y este es el primer artículo al que entran en nuestro sitio, les recomendamos visitar Primeros Pasos.
En este, y en otros dos artículos más, haremos una breve introducción a las RNA (Redes Neuronales Artificiales) ó ANN (Artificial Neural Networks), con el fin de abarcar los conceptos que rigen esta disciplina.
Desde hace unos años, quienes estamos en contacto con la ciencia a todo nivel, (desde un ingeniero electrónico que diseña software y/o hardware, hasta un petrofísico que hace una caracterización petrofísica de reservorios de petróleo), hemos sido bombardeados con los términos machine learning, deep learning, redes neuronales, etc.
Es más, muchos de nosotros hemos tenido acceso a software que trabaja con RNA, quizás hemos entrenado y aplicado modelos exitosamente, pero la verdad es que la simplicidad de los programas de computación actuales, y la complejidad matemática que implican las RNA, provocan que la mayoría de nosotros seamos capaces de obtener resultados, sin tener una noción clara sobre su validez. (incluidos nosotros).
Con el objetivo de tener un mejor entendimiento a la hora de trabajar con RNA, vamos a explorar algunos conceptos de este campo.
En este artículo, comenzaremos yendo desde lo más general hasta lo más específico, definiremos los términos Inteligencia Artificial, Machine Learning y Deep Learning, (los cuales suelen utilizarse en forma indistinta uno o el otro, pero, sin embargo, sus significados son diferentes). Esto nos ayudará a tener una mejor comprensión del panorama completo.
INTELIGENCIA ARTIFICIAL (IA)
Hay varias definiciones para este término. Si bien, todas son similares, y con el fin de serles lo más didáctico posible, compartiremos un par de ellas:
- La IA es una disciplina de la informática que intenta replicar la inteligencia humana a través de las computadoras, enfocándose sobre todo en el desarrollo de software.
- La IA es una rama de las ciencias computacionales encargada de estudiar modelos de cómputo capaces de realizar actividades propias de los seres humanos con base en dos de sus características primordiales: el razonamiento y la conducta.
No existe un acuerdo sobre la definición completa de inteligencia artificial, pero se han seguido cuatro enfoques, dos de ellos centrados en los humanos, y los otros dos centrados en la racionalidad:
Centrados en los humanos:
- Sistemas que se comportan como humanos.
- Sistemas que piensan como humanos.
Centrados en la racionalidad:
- Sistemas que se comportan racionalmente.
- Sistemas que piensan racionalmente.
ℹ️ En este LINK podrán encontrar más información sobre Inteligencia Artificial.
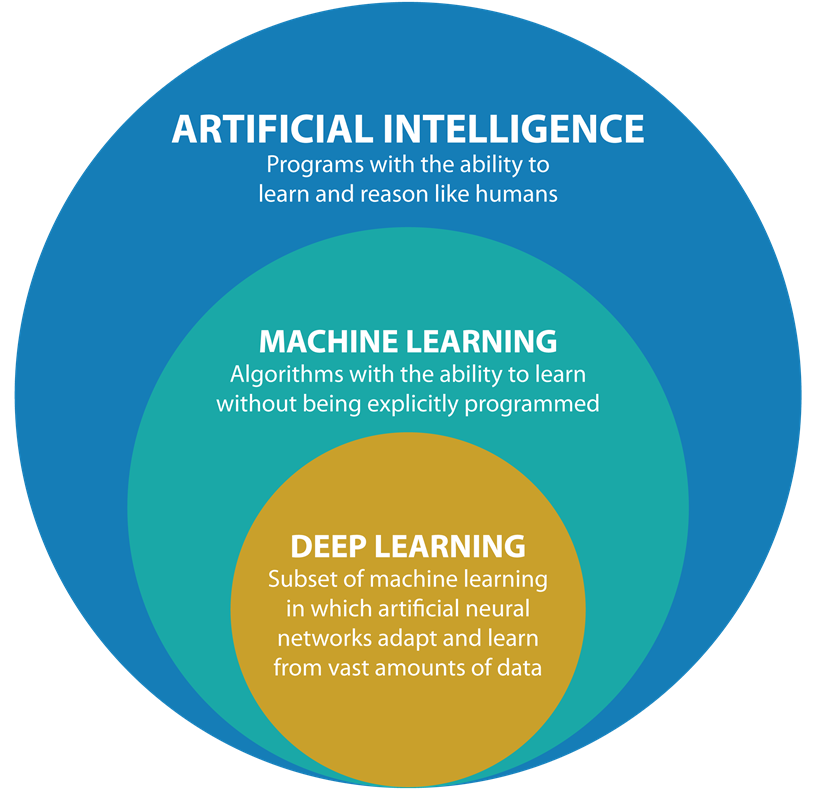
Figura 1: IA, ML, DL (Fuente: medium.com)
MACHINE LEARNING o APRENDIZAJE AUTOMÁTICO
Una de las claves de la IA está en el aprendizaje, justamente la disciplina del Aprendizaje Automático o Machine Learning, se ocupa de este reto.
A partir de esto, definiremos al Aprendizaje Automático como una disciplina del campo de la Inteligencia Artificial que, a través de algoritmos, otorga a las computadoras la capacidad de análisis predictivo, (identificar patrones en un conjunto de datos y elaborar predicciones en base a ellos), sin necesidad de ser programados.
Hay muchos tipos diferentes de algoritmos de Aprendizaje automático, entre los que se encuentran el aprendizaje supervisado, no supervisado y reforzado, los algoritmos genéticos, el aprendizaje basado en reglas de asociación, los algoritmos de agrupamiento, los árboles de decisión, las máquinas de vectores de soporte y las redes neuronales.
Actualmente, los algoritmos más populares dentro de este campo son los de Deep Learning.
ℹ️ Si desean más información sobre Machine Learning, ejemplos, etc., pueden encontrarlos haciendo click en el siguiente LINK .
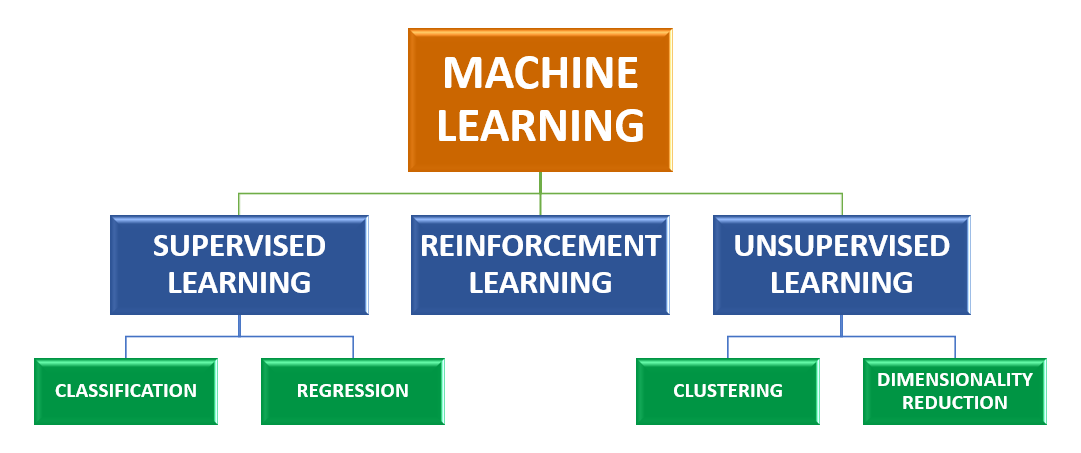
Figura 2: Machine Learning
APRENDIZAJE SUPERVISADO (SUPERVISED LEARNING)
En este tipo de entrenamiento, contamos con datos duros, o labels, para entrenar. Una vez tenemos el modelo entrenado, podemos hacer predicciones al entrar nuevos datos o features.
En este método de entrenamiento tenemos 2 tipos diferentes de aprendizaje: CLASSIFICATION y REGRESSION
CLASSIFICATION o CLASIFICACIÓN
En este tipo de modelado, tenemos datos duros y queremos separarlos en grupos, o sea, clasificarlos. Por ejemplo, si contamos con datos duros, (features), de altura y peso de personas de distinto sexo, debemos poder predecir el sexo de una persona x con peso y altura específicos.
Las métricas que nos indican un buen ajuste, o no, del modelo son: Precisión, Exactitud. Cuál de ellas se toma en cuenta, depende de la situación.
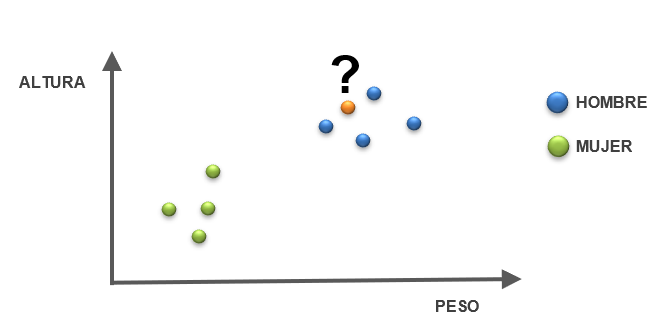
Figura 3: SUPERVISED LEARNING: CLASSIFICATION
REGRESSION o REGRESIÓN
Es cuando tenemos varios datos duros y con eso formamos una función continua, entonces al tener datos en el eje x, interceptamos el punto con la función, y eso nos representa el resultado. Por ejemplo, datos o features de: superficie del terreno en m², cantidad de ambientes, ubicación, etc., de casas para predecir su valor de mercado.
Las métricas para regresión son: MAE (Min Absolute Error), MSE (Min Square Error), RMSE (Root Min Square Error), etc.
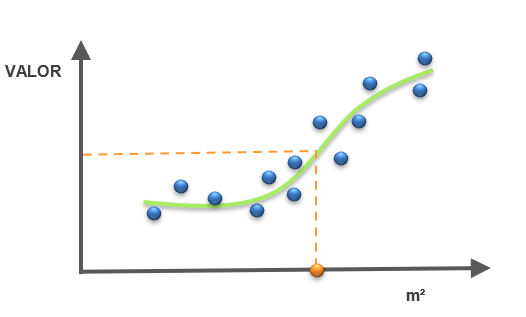
Figura 4: SUPERVISED LEARNING: REGRESSION
FLUJOS DE TRABAJO O WORKFLOWS
En entrenamiento supervisado, es aconsejable comprobar cómo se comporta nuestro modelo al encontrarse con datos nuevos. Esto nos va a ayudar a conservarlo como está o, reprocesarlo para mejorarlo. Con este fin, generalmente los datos de entrada se dividen, (split), en 2 ó 3 sets . Los sets son denominados train set, test set, validation set según su función. Nosotros vamos a utilizar uno o el otro dependiendo de nuestros objetivos, y de la cantidad de datos con la que contemos.
Hold-out for model evaluation (train, test)
En este caso dividimos los datos en 2 sets: training data (~70% del total) y testing data(~30% del total). Primero entrenamos nuestro modelo con la training data. Aplicamos este modelo a nuestra testing data, y allí evaluamos si debemos modificar, o no, el mismo.
Al quedar satisfechos luego de x evaluaciones, obtendremos nuestro modelo final y sus hiperparámetros. (Acá hay 2 opciones, podemos dejarlo como final, o podemos reentrenar este modelo final con todos los los datos (train + test), con el riesgo de caer en overfitting que esto implica).
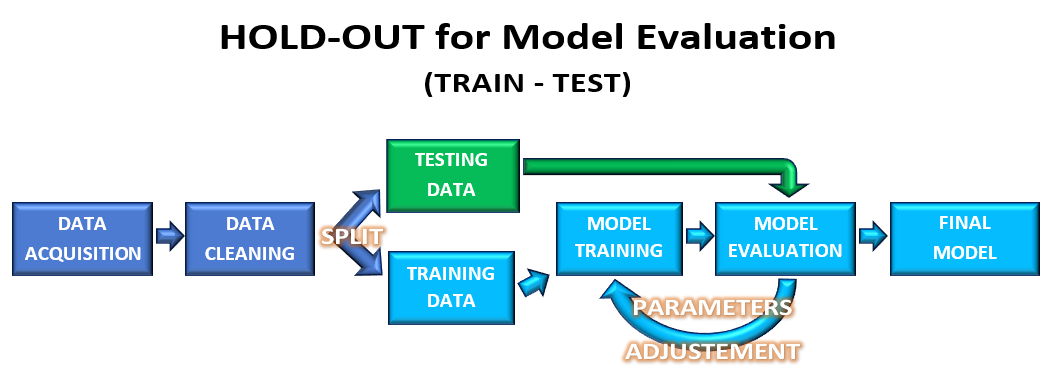
Figura 5: SUPERVISED LEARNING WORKFLOW: Hold-out for model evaluation
Hold-out for model selection (train, validation, test)
En este caso, los datos se particionan en 3 sets (train,validation,test). Con las particiones train data, y validation data, voy a actuar exactamente igual que en el caso anterior. Voy a entrenar con la partición train data, y voy a validarlos con la validation data.
Cuando tengo el modelo deseado, se lo aplico al conjunto de datos formados por estas 2 particiones (train data, validation data), y así obtengo mi modelo final.
Por último, voy a evaluar ese modelo final utilizando la partición test data, con el objetivo de obtener una métrica para ver qué tan confiable es. (no voy a modificar en absoluto mi modelo final, sólo voy a medir su eficiencia ante nuevos datos).
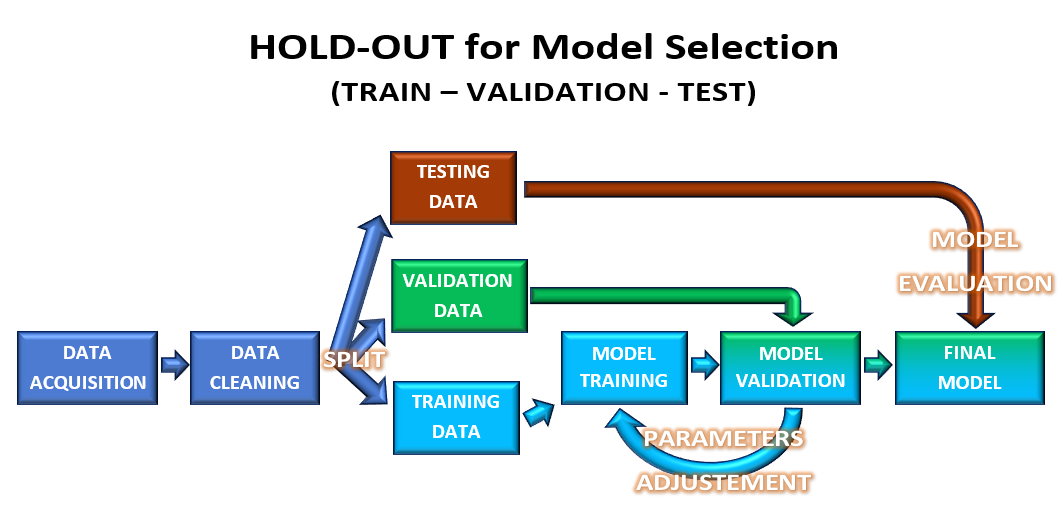
Figura 6: SUPERVISED LEARNING WORKFLOW: Hold-out for model selection
APRENDIZAJE NO SUPERVISADO (UNSUPERVISED LEARNING)
En el entrenamiento no supervisado no tenemos datos duros, entonces nos vemos obligados a tratar de buscar patrones en la data para así poder encontrar algún tipo de estructura.
En este tipo de entrenamiento tenemos que tratar de agrupar datos similares dentro de conjuntos. Esta tarea va a depender de la persona que interprete los datos.
Las métricas para este tipo de entrenamiento no son fáciles de evaluar, podemos nombrar: cluster homogeneity, rand index.
Por ejemplo, contamos con datos de Peso y Altura de perros, y queremos ver si con esto podemos predecir la raza. En realidad, lo que hacemos es comparar cada punto con el resto y ver qué tan similares, o no, pueden ser. En el ejemplo, podemos inferir que hay 2 grupos diferentes de “algo distintivo” (puede ser raza, sexo, edad, etc.). No sabemos qué los separa, lo único que podemos hacer es diferenciarlos en 2 grupos. Es bueno recordar que esta clasificación va a depender del intérprete de los datos.
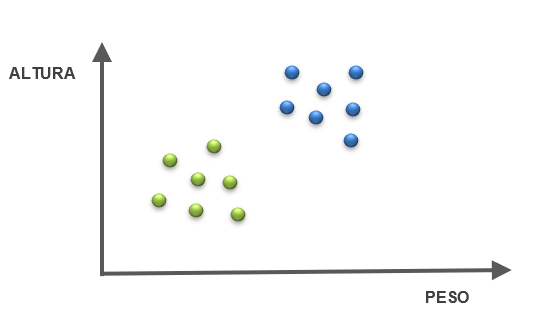
Figura 7: Datos de altura y peso de perros. Hay 2 conjuntos de perros diferenciables según estos labels pero, con sólo esta información, no sabemos qué representa cada uno.
Los Clustering algorithms, o Algoritmos de agrupamiento, son herramientas que nos permiten realizar la tarea de agrupar un conjunto de puntos de datos que son similares entre sí, en función de su relación con los puntos de datos circundantes. A cada uno de estos conjuntos de datos se los denomina cluster.
Hay varios Algoritmos de agrupamiento, de los cuales solamente nombraremos K-Means y Affinity propagation. La elección de uno u otro va a depender de los datos con los que contemos, como así también de nuestros objetivos.
ℹ️ En este LINK podrán encontrar más información sobre algoritmos de agrupamiento disponibles en scikit-learn.
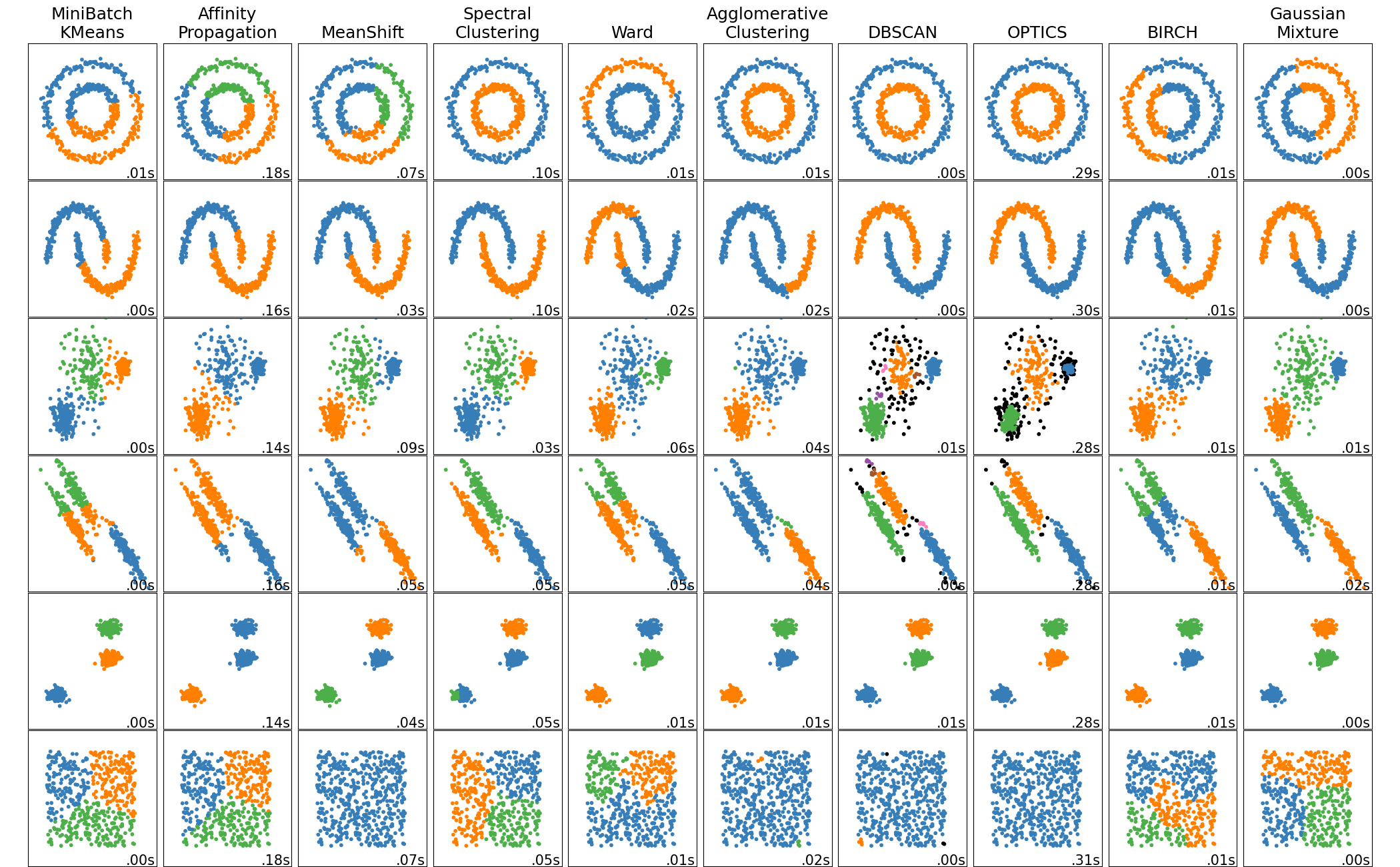
Figura 8: Comparación de algoritmos de agrupamiento en scikit-learn (Fuente: scikit-learn)
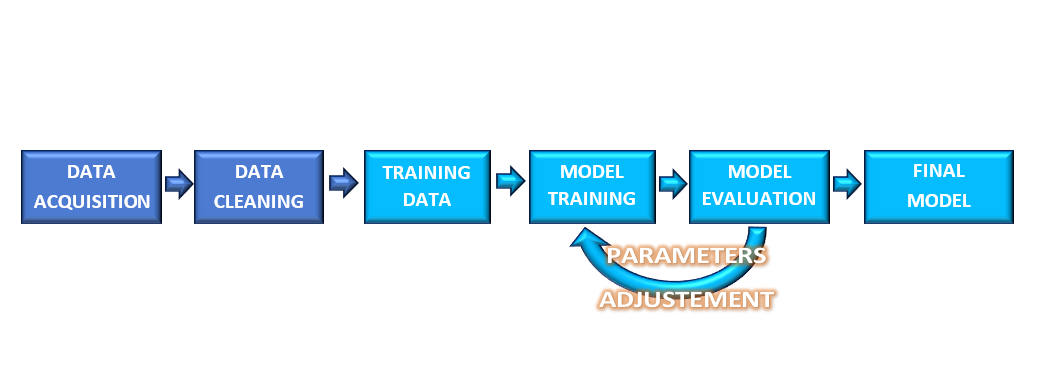
Figura 9: UNSUPERVISED LEARNING WORKFLOW
APRENDIZAJE REFORZADO (REINFORCEMENT LEARNING)
El entrenamiento reforzado va aprendiendo mediante prueba y error las acciones más acertadas para lograr un objetivo. (Aprender a jugar un video juego, manejar un auto, etc).
Las métricas son más obvias que las anteriores, ya que la evaluación entra dentro del entrenamiento. Una métrica sería, qué tan bien lleva a cabo el modelo la tarea asignada.
DEEP LEARNING o APRENDIZAJE PROFUNDO
Deep Learning es un conjunto de algoritmos de Machine Learning que utilizan estructuras o capas de redes neuronales para encontrar patrones en los datos.
El término deep se aplica a la cantidad de capas que utiliza el modelo, (generalmente decenas). Hay 3 tipos de capas en una red neuronal artificial:
- Capa de entrada o Input Layer.
- Capa oculta o Hidden Layer.
- Capa de salida o Output Layer.
Estas estructuras lógicas se asemejan en mayor medida a la organización del sistema nervioso de los mamíferos, teniendo capas de unidades de proceso, (neuronas artificiales), que se especializan en detectar determinadas características existentes en los objetos percibidos.
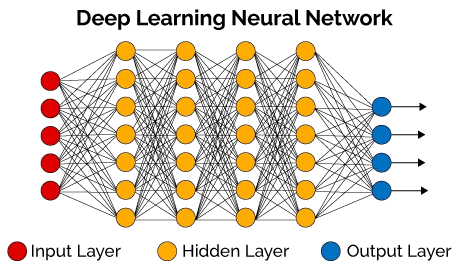
Figura 10: Estructura de una Red Neuronal de Aprendizaje Profundo (Fuente: openwebinars.net)
En resumen, hemos definido 3 conceptos generales muy importantes dentro del campo de la inteligencia artificial. En Introducción a las Redes Neuronales Artificiales (RNA) - Parte 2 nos concentraremos en el funcionamiento de las neuronas artificiales o nodos.
Les agradecemos su tiempo y esperamos fervientemente que hayan disfrutado este artículo. Si tienen alguna consulta, desean hacer algún comentario o sugerencia para mejorar el contenido, o simplemente indicarles qué les pareció este artículo, debajo pueden hacerlo.
Esperamos reencontrarlos en algún otro artículo del sitio. Hasta luego!
Tags
Recent Posts