Crear múltiples crossplots densidad-neutrón utilizando plotly

En este artículo graficaremos múltiples crossplots Den-Neu utilizando plotly express, una API perteneciente a la librería plotly.
Bienvenidas/os!!, muchas gracias por visitarnos, si están comenzando en Python y este es el primer artículo al que entran en nuestro sitio, les recomendamos visitar Primeros Pasos.
ℹ️ Les recordamos que todos los ejemplos de códigos en nuestro sitio web van a encontrarlos en nuestro repositorio GitHub. Los códigos de este artículo los encontrarán en plotly_multiples-crossplots.ipynb.
ℹ️ Toda la información de archivos .las/.csv contenida en este sitio web es información liberada por sus propietarios..En esta oportunidad vamos a trabajar con plotly, una librería gráfica muy poderosa que genera visualizaciones increíblemente interactivas y de muy buena calidad, características que la transforma en una herramienta muy útil a la hora de trabajar con scatterplots (o crossplots, como se suelen denominar en el ámbito de la petrofísica a este tipo de gráficos).
Vale la pena destacar que hasta ahora veníamos utilizando matplotlib y/o seaborn para visualización de datos, eso es porque mayormente hemos hecho gráficos estilo logs. En este artículo veremos que existen grandes ventajas a la hora de utilizar plotly para graficar scatterplots.
ℹ️ Ya realizamos una comparación entre plotly y matplotlib en nuestro artículo primeros pasos. Si lo desean, pueden entrar aquí para revisarla.
Hemos decidido utilizar la API, (Application Programming Interface), plotly express ya que es conveniente por la sencillez del código para cumplir con nuestro objetivo, el cual es crear múltiples scatterplots con datos de varios pozos, interactuar con los mismos (hacer zoom, modificar escalas directamente en el gráfico, obtener valores de los puntos del gráfico deslizando el puntero del mouse sobre ellos, etc), y poder compararlos visualmente.
Sin más, comencemos:
IMPORTAR LIBRERÍAS
La primera celda generalmente la utilizamos para importar TODAS las librerías necesarias para cargar, manejar y visualizar los datos en el resto del notebook.
ℹ️ Es aconsejable importar todas las librerías que vayamos necesitando a lo largo de todo el notebook en una misma celda al comienzo del mismo, y no tener líneas de código import en varias celdas.import lasio
import pandas as pd
import os
from IPython.display import clear_output
import plotly.express as px
CARGA DE LOS DATOS
La carga/importación de datos la haremos utilizando la librería lasio.
Seguidamente obtendremos los nombres de todos los archivos .las que contienen los datos de los pozos.
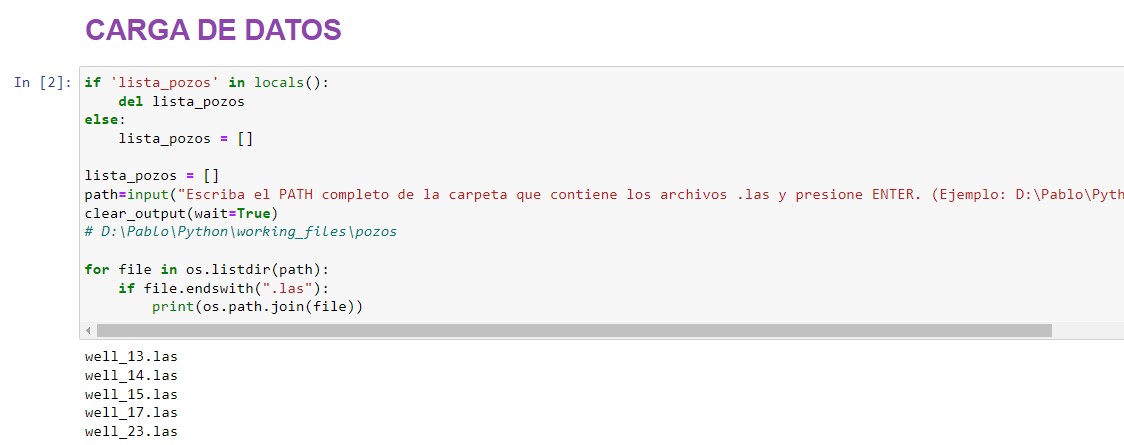
⚠️ Todos los archivos .las deben estar dentro de una misma carpeta, ya que el siguiente código busca los archivos .las dentro de una única carpeta (no va a encontrar archivos .las si están en subcarpetas de esta carpeta).Al correr esta celda, nos pedirá un PATH. Ahí deberemos escribir la ruta completa de la carpeta, luego debemos 👉presionar la tecla INTRO👈. (En el ejemplo escribimos D:\Pablo\Python\working_files\pozos).
ℹ️ el path está comentado en el código. Esto es útil para copiarlo y pegarlo directamente cada vez que utilicemos el notebook.if 'lista_pozos' in locals():
del lista_pozos
else:
lista_pozos = []
lista_pozos = []
path=input("Escriba el PATH completo de la carpeta que contiene los archivos .las y presione INTRO. (Ejemplo: D:\Pablo\Python\working_files)")
clear_output(wait=True)
# D:\Pablo\Python\working_files\pozos
for file in os.listdir(path):
if file.endswith(".las"):
print(os.path.join(file))
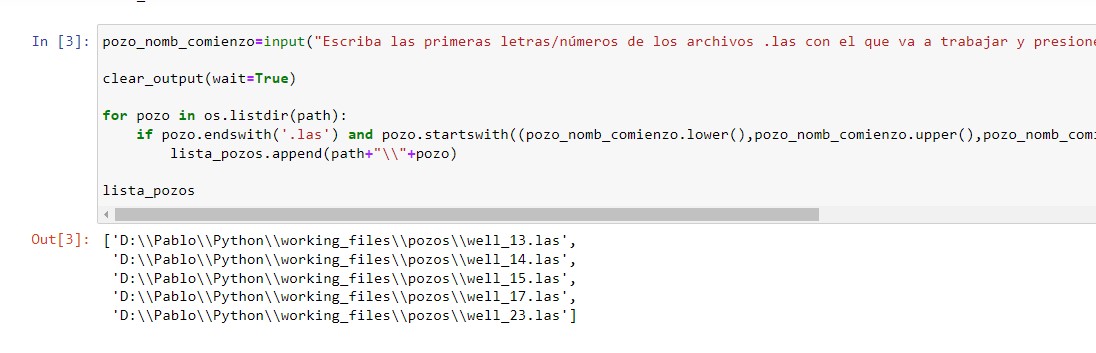
Una vez que identificamos con cuáles pozos vamos a trabajar, utilizaremos la siguiente celda para seleccionarlos. Para ello, vamos a introducir los primeros caracteres del nombre de los archivos cuando nos lo pida la celda, luego debemos 👉presionar la tecla INTRO👈 (En el ejemplo, escribimos well).
⚠️ Si con este código no agregamos todos los archivos .las que deseamos a la lista, podemos volver a correr la celda utilizando otros caracteres, cada vez que lo hagamos vamos a incluir elementos a la lista. También podemos agregarlos manualmente utilizando append u otra opción de Listas en Python .
pozo_nomb_comienzo=input("Escriba las primeras letras/números de los archivos .las con el que va a trabajar y presione INTRO,si va a utilizar todos los .las de la carpeta, solo presione INTRO")
clear_output(wait=True)
for pozo in os.listdir(path):
if pozo.endswith('.las') and pozo.startswith((pozo_nomb_comienzo.lower(),pozo_nomb_comienzo.upper(),pozo_nomb_comienzo.capitalize())):
lista_pozos.append(path+"\\"+pozo)
lista_pozos
CREACIÓN DEL DATAFRAME
Ahora que obtuvimos una lista con todas las rutas completas, (en el formato adecuado), a los archivos con datos de pozo con los que queremos trabajar, vamos a pasar todos los datos de cada archivo a un solo dataframe pandas.
Para ello, seguiremos estos pasos:
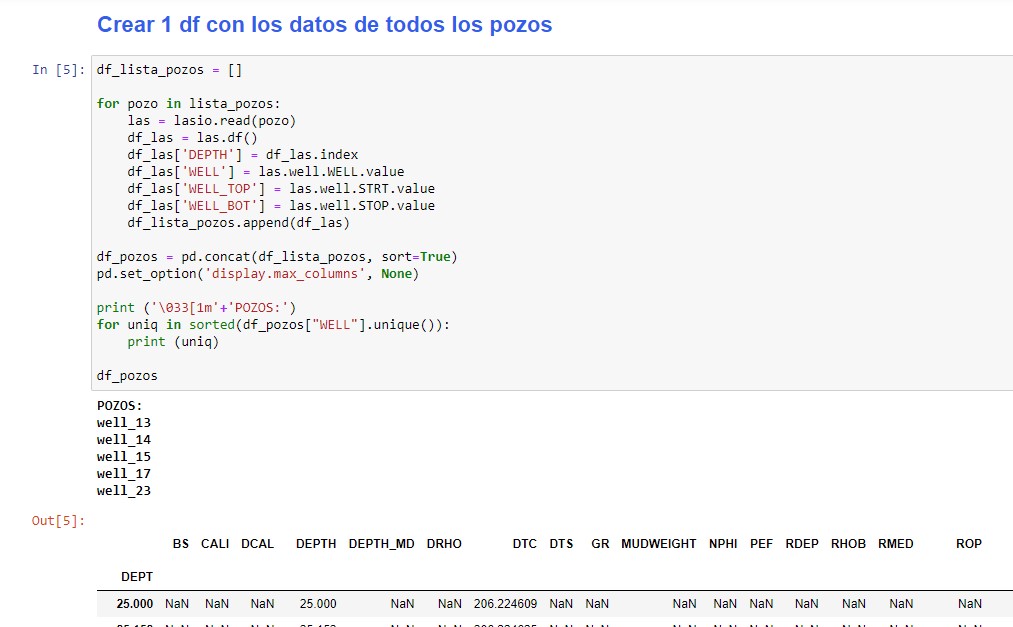
- Crearemos una lista vacía llamada df_lista_pozos .
- Con un for loop iteraremos cada elemento de la lista lista_pozos y copiaremos todos sus datos a df_lista_pozos. Además, en cada iteración, crearemos adicionalmente las columnas DEPTH, WELL, WELL_TOP, WELL_BOT a partir de los valores de los diccionarios de cada objeto lasio.
- Una vez que tengamos df_lista_pozos, lo convertiremos a dataframe pandas.
df_lista_pozos = []
for pozo in lista_pozos:
las = lasio.read(pozo)
df_las = las.df()
df_las['DEPTH'] = df_las.index
df_las['WELL'] = las.well.WELL.value
df_las['WELL_TOP'] = las.well.STRT.value
df_las['WELL_BOT'] = las.well.STOP.value
df_lista_pozos.append(df_las)
df_pozos = pd.concat(df_lista_pozos, sort=True)
pd.set_option('display.max_columns', None)
print ('\033[1m'+'POZOS:')
for uniq in sorted(df_pozos["WELL"].unique()):
print (uniq)
df_pozos
Ya teniendo el dataframe, podemos aprovechar los beneficios de pandas y hacer un control de calidad, o al menos explorar de manera sencilla los datos (Solamente mostraremos un ejemplo).
ℹ️ Si desean hacer un control de calidad de los datos más exhaustivo del dataframe con pandas, pueden chequear métodos pandas útiles en el artículo Manejo de datos utilizando pandas .
df_pozos.groupby('WELL').mean()
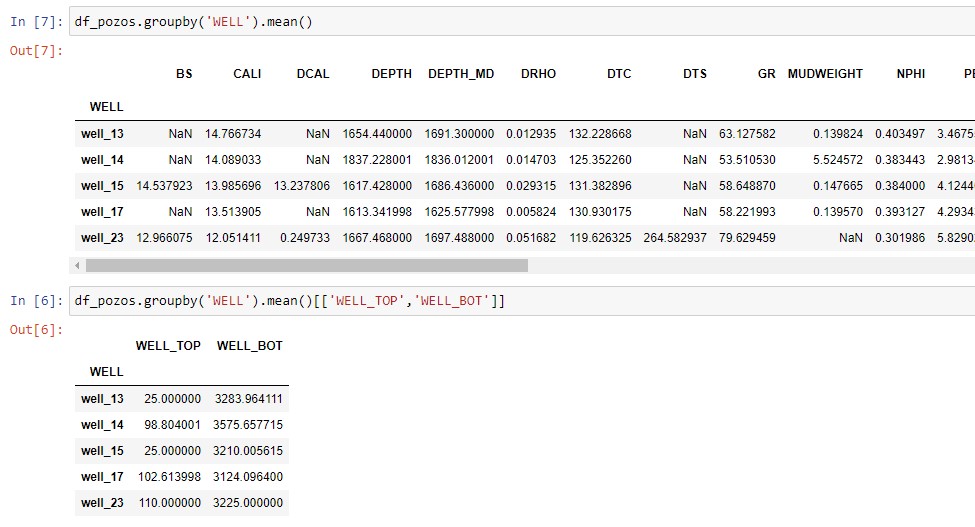
GRÁFICO TIPO SCATTERPLOT EN PLOTLY EXPRESS
Es la hora de visualizar los datos de densidad y neutrón en un scatterplot, o crossplot, como deseen llamarlo. Para ello utilizaremos plotly express.
plotly express es una API de la librería plotly. Es muy útil para crear gráficos de muy alta calidad con una muy buena interacción usuario-gráfico. Eso sí, es limitado en cuanto a ir un poco más allá si queremos hacer un plot muy específico. (Por ejemplo, permite sólo una traza por gráfico (un solo par x,y), etc).
Sin embargo, tiene argumentos muy funcionales que nos permitirán trabajar con códigos muy sencillos, pero que realizarán tareas que con otras librerías gráficas nos llevaría tiempo y muchas más líneas de código.
La sintaxis que utilizaremos es:
px.scatter(dataframe, x, y, color, range_color, color_continuous_scale, size, facet_col, facet_col_wrap)
- dataframe: Nombre del dataframe.
- x: Nombre la columna dentro del dataframe para el eje x.
- y: Nombre la columna dentro del dataframe para el eje y.
- color: Nombre de la columna del dataframe que va a utilizar plotly para diferenciar los puntos del plot pintándolos de diferentes colores. Podemos introducir columnas con valores numéricos, o columnas con letras/palabras (categorías).
- color_continuous_scale: Nombre del mapa de colores o cmap (Si utilizamos valores numéricos en color).
- range_color: Rango de valores, (máx, mín), del parámetro color_continuous_scale, si utilizamos valores numéricos en el argumento color.
- size: Nombre de la columna del dataframe que definirá el tamaño de los puntos del scatterpot. (si plotly encuentra valores nulos en esta columna, nos dará error sin graficarnos nada).
- facet_col: Columna del dataframe que va a utilizar para hacer los subplots.
- facet_col_wrap: Cantidad de subplots por fila.
Como solemos hacer, vamos a crear variables para poder hacer modificaciones menores al código cada vez que deseemos cambiar algún dato de entrada como puede ser, nombre de alguna de las columnas, alguna de las escalas, etc.
Además, antes de crear los gráficos, vamos a generar un dataframe sólo con las curvas que necesitamos para el plot, con el fin de tratar de no consumir muchos recursos del sistema al visualizarlos.
################################### DATOS ####################################
##### Curvas #####
crv_x = 'NPHI'
crv_y = 'RHOB'
crv_color= 'GR'
crv_facet = 'WELL'
crv_size = 'CALI'
### Escalas curvas ###
crv_x_izq = 0
crv_x_der = 0.8
crv_y_aba = 3.2
crv_y_arr = 1.2
color_izq = 0
color_der = 120
color_cmap = px.colors.sequential.Hot_r
################################### CODIGO ####################################
##### Creamos un df solo con las curvas del grafico + DETPH #####
plotdf = pd.DataFrame()
crv_copy= df_pozos[[crv_x,crv_y,crv_color,crv_facet,crv_size,'DEPTH']]
plotdf = crv_copy.copy(deep=True)
df = plotdf[df_pozos[crv_size].notnull()]
##### PLOT #####
fig = px.scatter(df, x=df[crv_x], y=df[crv_y],
color=df[crv_color],range_color=[color_izq,color_der], color_continuous_scale=color_cmap,
size=df[crv_size],
facet_col=df[crv_facet],facet_col_wrap=2)
fig.update_layout(autosize=False, width=1000, height=1200)
fig.update_coloraxes(colorbar_len=0.5)
fig.update_xaxes(range=[crv_x_izq, crv_x_der])
fig.update_yaxes(range=[crv_y_aba, crv_y_arr])
fig.show()
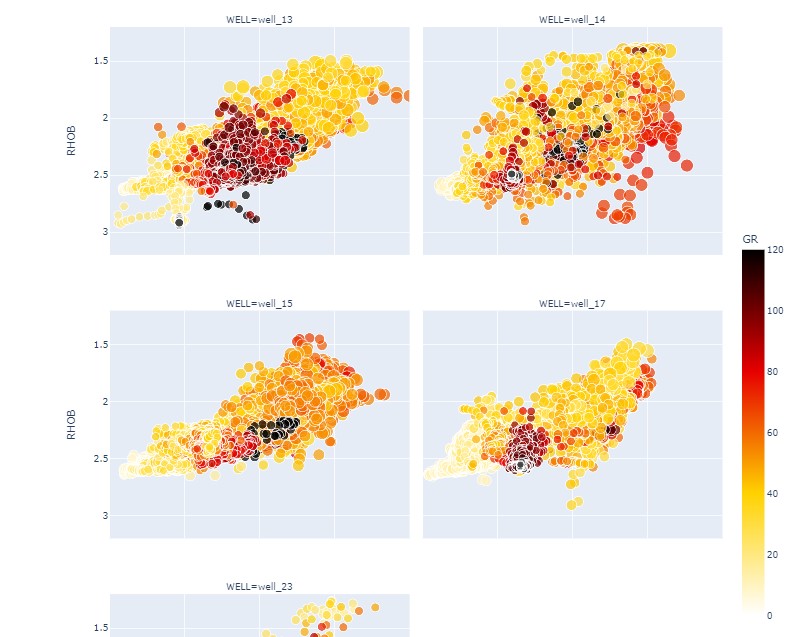
En resumen, cargamos varios archivos .las utilizando lasio. Copiamos todos sus datos a un único dataframe pandas, y seguidamente graficamos múltiples scatterplots con plotly express utilizando dichos datos.
Les agradecemos su tiempo y esperamos fervientemente que hayan disfrutado este artículo. Si tienen alguna consulta, desean hacer algún comentario o sugerencia para mejorar el contenido, o simplemente indicarles qué les pareció este artículo, debajo pueden hacerlo.
Esperamos reencontrarlos en algún otro artículo del sitio. Hasta luego!
Tags
Recent Posts