Manejo de datos utilizando pandas

Nos toca una tarea que nos traerá muchos beneficios, aprender a trabajar con pandas. pandas nos dará muchas herramientas para el manejo de los datos de implementación sencilla. Pero aún hay más, también podremos utilizarla con librerías de visualización como matplotlib, seaborn, etc, para crear gráficos de manera más simple y enfocada a nuestras necesidades.
Bienvenidas/os!!, muchas gracias por visitarnos, si están comenzando en Python y este es el primer artículo al que entran en nuestro sitio, les recomendamos visitar Primeros Pasos.
ℹ️ Les recordamos que todos los ejemplos de códigos en nuestro sitio web van a encontrarlos en nuestro repositorio GitHub. Los códigos de este artículo los encontrarán en pandas_tips.ipynb.
En esta oportunidad, vamos a ver varios métodos que nos ofrece pandas para la creación y el manejo de dataframes.
Un dataframe es una estructura tabular de datos que contiene 3 elementos principales, filas o rows, columnas o columns, y datos. Generalmente cada columna tiene un nombre o header. Así mismo, el dataframe consta de un índice o index, lo cual me identifica cada fila del dataframe.
Algo muy útil y conveniente en pandas, es que podemos definir cualquier columna como índice (por ejemplo, en el caso de datos de pozo, es muy provechoso utilizar la columna de profundidad como índice).
ℹ️ Para trabajar con pandas utilizaremos mucho la librería numpy. Por ello, van a poder encontrar varios tips de numpy en el archivo numpy.ipynb almacenado en nuestro repositorio GitHub.
Vamos a empezar entonces con los métodos de pandas. Aquí le presentamos los que veremos en este artículo:
MÉTODOS
- Crear DataFrame desde hoja excel
- Crear DataFrame desde un array o una list
- Visualizar datos del dataframe
- Ver nombre y tipo de cada columna
- Ver estadísticas de las curvas numéricas
- Ver valores mínimo, máximo, media, mediana
- Filtro simple
- Filtro doble
- Concatenar dataframes
- Hacer un merge de dataframes
- Correr función al dataframe
- Correr función a una columna del dataframe
- Reemplazar columnas por filas y viceversa
- Guardar dataframe en hoja excel
Antes de empezar, hay que importar las librerías que usaremos en el notebook:
import numpy as np
import pandas as pd
Crear DataFrame desde hoja excel
pd.read_excel (..\hoja.xlsx')
Este comando lee la hoja excel que le especifiquemos en el path e inserta los datos dentro de un dataframe.
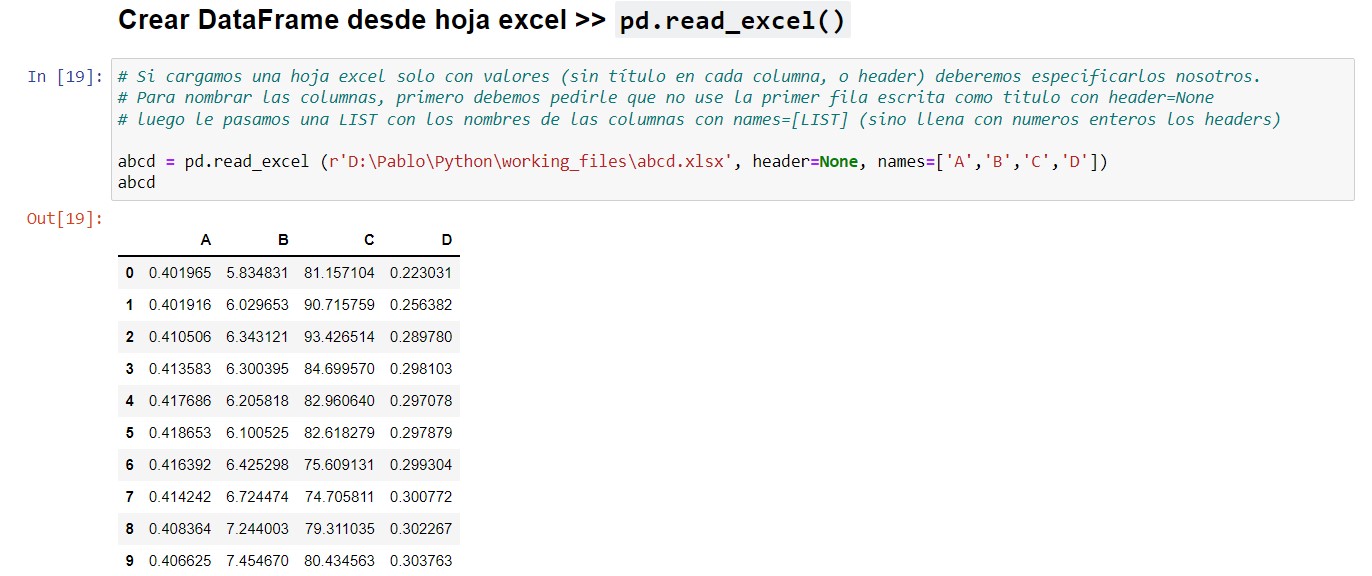
⚠️ Si cargamos una hoja excel sólo con valores, (sin título, o "header" para cada columna), deberemos especificar los headers nosotros. Para hacerlo, tendremos primero que pedirle que no use la primera fila escrita como header con header=None. Luego le pasamos una LIST con los nombres de las columnas con names=[LIST]. La cantidad de elementos de la LIST debe coincidir con la cantidad de columnas de la hoja excel (Si no le especificamos nombres, le asigna números enteros a cada header como nombre). | VOLVER⤴️
# Si cargamos una hoja excel sólo con valores (sin título en cada columna, o header) deberemos especificarlos nosotros.
# Para nombrar las columnas, primero debemos pedirle que no use la primera fila escrita como titulo con header=None
# luego le pasamos una LIST con los nombres de las columnas con names=[LIST] (sino llena con numeros enteros los headers)
abcd = pd.read_excel (r'D:\Pablo\Python\working_files\abcd.xlsx', header=None, names=['A','B','C','D'])
abcd
Crear DataFrame desde un array o una list
pd.DataFrame(ARRAY ó LIST,columns=['col1'...])
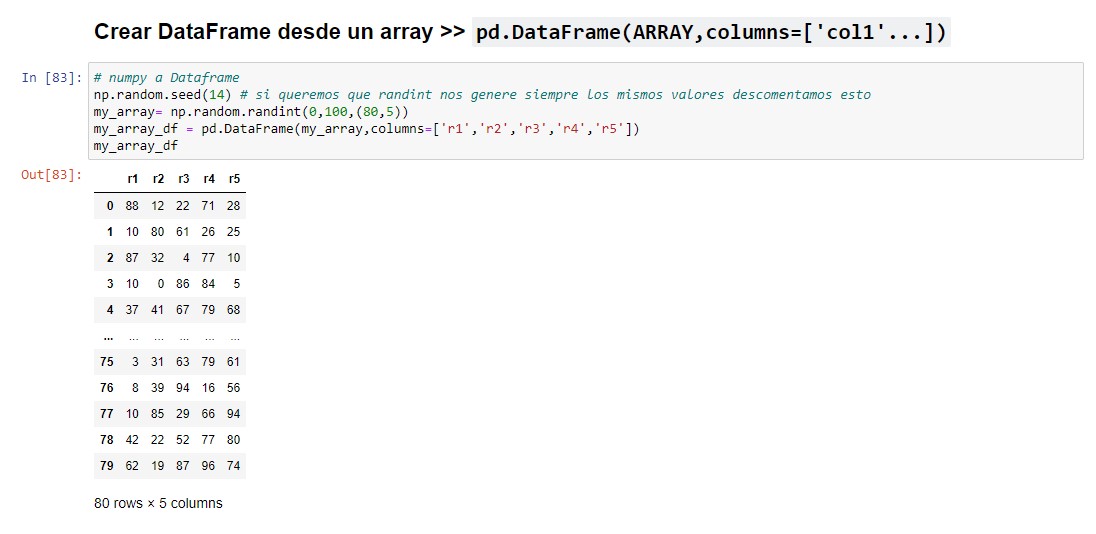
Si queremos convertir un array o una lista a dataframe este es el código. Sólo mostraremos el caso con array, porque es exactamente la misma sintaxis para la lista.
ℹ️ En el archivo pandas_tips.ipynb alojado en nuestro repositorio GitHub van a encontrar el ejemplo con la lista y algo más de material. | VOLVER⤴️
# numpy a Dataframe
np.random.seed(14) # si queremos que randint nos genere siempre los mismos valores
my_array= np.random.randint(0,100,(80,5)) # Generamos el array
my_array_df = pd.DataFrame(my_array,columns=['r1','r2','r3','r4','r5'])
my_array_df
Visualizar datos del dataframe
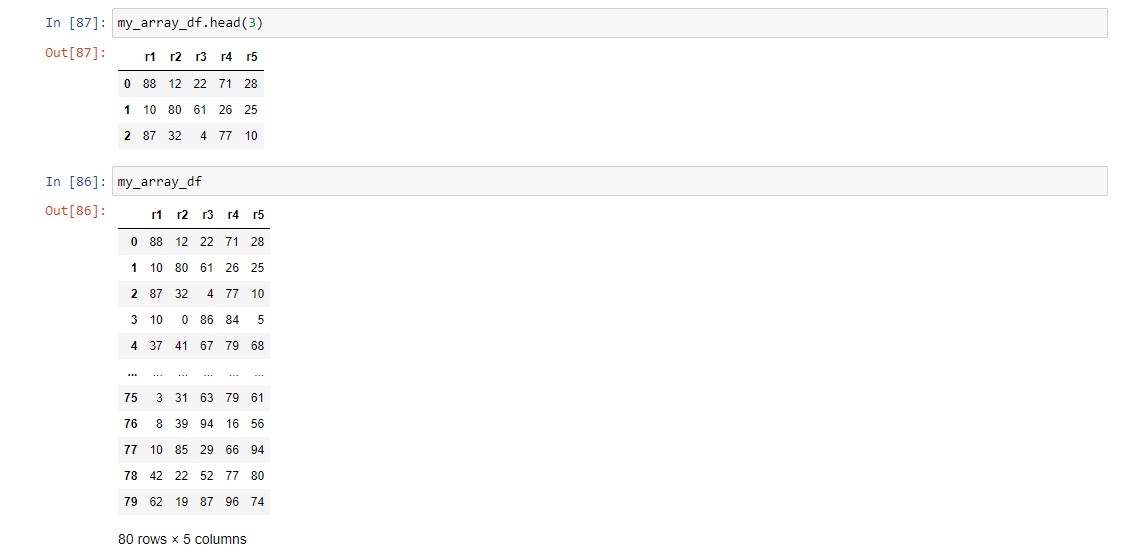
df df.head(n) df.tail(n)
Les presentamos 3 maneras de ver los primeros/últimos n datos del dataframe.
ℹ️ En este artículo, df vamos a tomarlo de manera genérica representando cualquier nombre que pueda tomar un dataframe.df nos va a mostrar las primeras 5 filas y las últimas 5. df.head(n) nos mostrará las primeras n filas, mientras que df.tail(n) las últimas n filas (5 en ambos casos si no le especificamos n). | VOLVER⤴️
my_array_df.head(3)
Ver nombre y tipo de cada columna
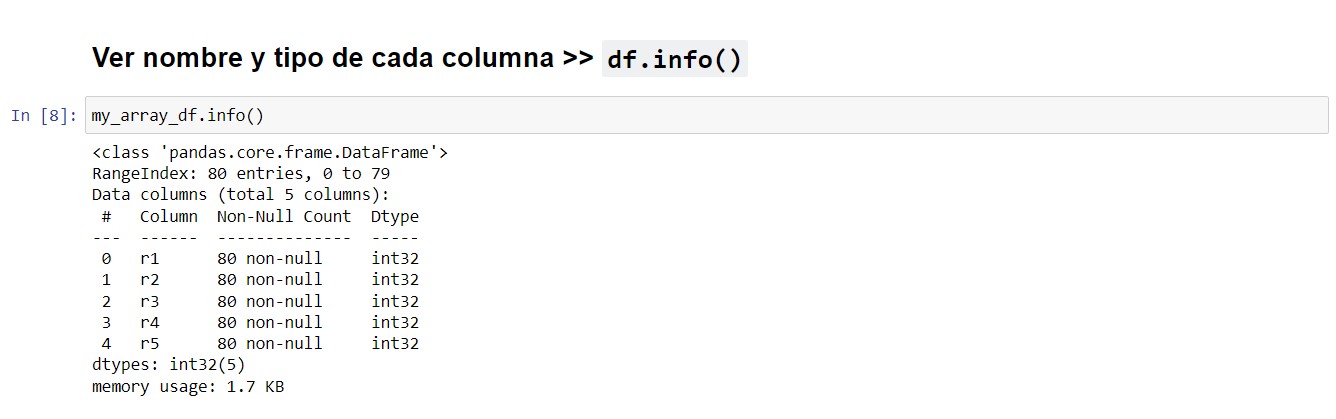
df.info()
Método para ver nombre y tipo de cada columna. | VOLVER⤴️
my_array_df.info()
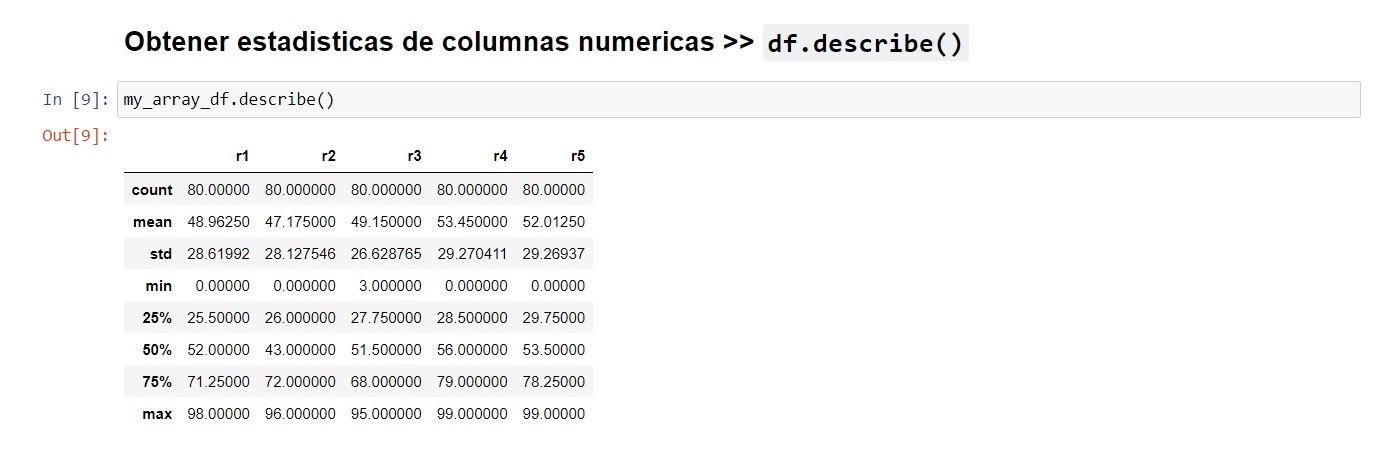
Ver estadísticas de las curvas numéricas
df.describe()
Método para ver estadísticas de las columnas numéricas presentes en el dataframe. | VOLVER⤴️
my_array_df.describe()
Ver valores mínimo, máximo, media, mediana
df['col'].min() df['col'].max() df['col'].mean() df['col'].median()
Métodos para ver estadísticas particulares de la columna/s, (valor máximo, mínimo, media, mediana), presentes en el dataframe. | VOLVER⤴️
my_array_df['r1'].min(),my_array_df['r1'].mean(),my_array_df['r1'].median(),my_array_df['r1'].max()

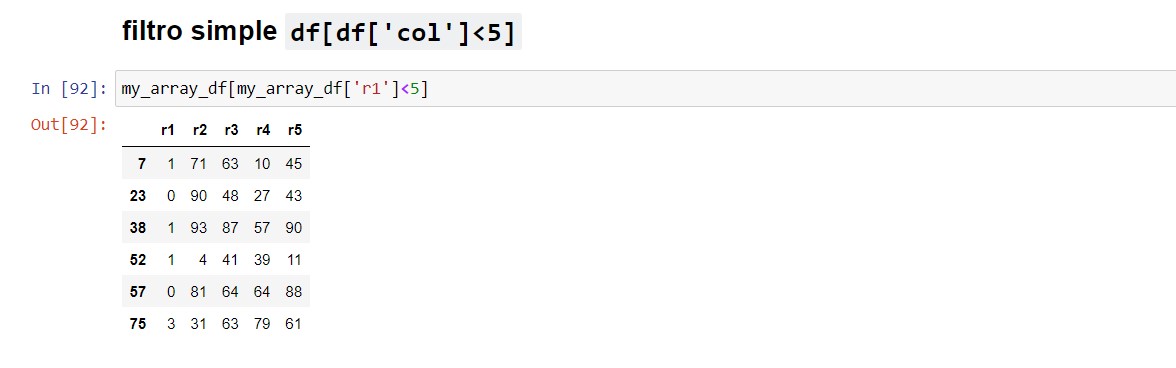
Filtro simple
df[df['col1']<5]
Acá veremos cómo filtrar los datos utilizando los valores de una columna (Si lo deseáramos, podríamos sacar el resultado del filtro como dataframe. También podemos utilizar la sintaxis del filtro dentro del código de matplotlib o algún otro visualizador que lo permita). | VOLVER⤴️
ℹ️ En este caso utilizamos el operador "<", pero acepta cualquiera de ellos.my_array_df[my_array_df['r1']<5]
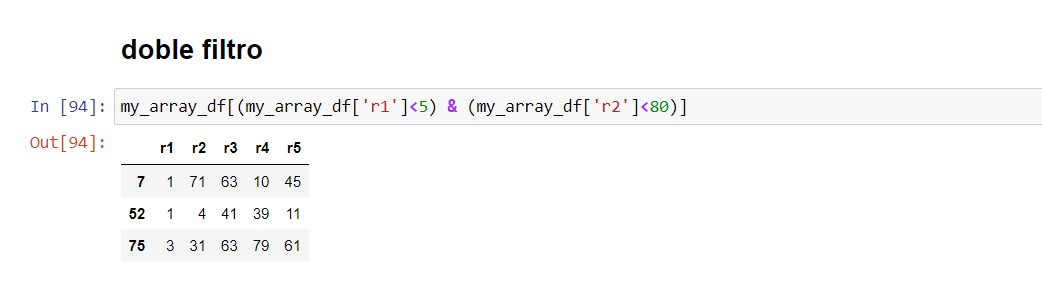
Filtro doble
df[df(['col1']<5) & (df['col2']<80)]
Acá veremos cómo filtrar los datos utilizando los valores de 2 columnas (Si lo deseáramos, podríamos sacar el resultado del filtro como dataframe. También podemos utilizarlo dentro del código de matplotlib o algunos otros visualizadores). | VOLVER⤴️
my_array_df[my_array_df['r1']<5]
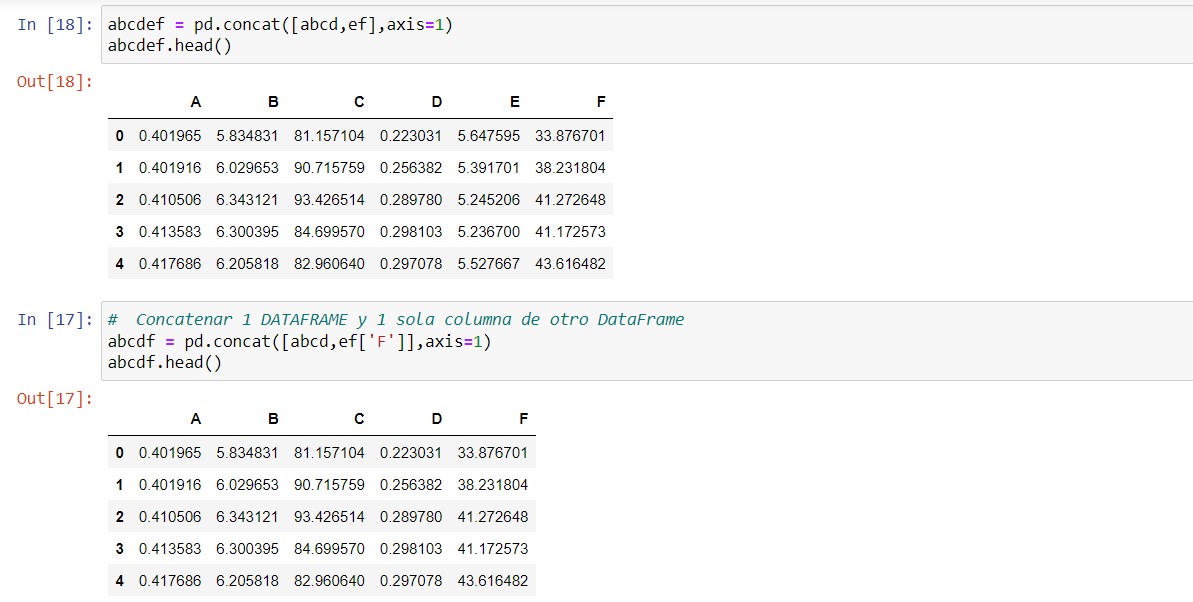
Concatenar dataframes
pd.concat([df1,df2,...,dfn],axis=1)
Con este método vamos a poder unificar los datos de 2 ó más dataframes en uno solo.
Tenemos que tener en cuenta que pd.concat solamente copia todas las columnas de los dataframe a un destino sin chequear si tienen el mismo nombre. NO reconoce columnas con el mismo nombre. Si queremos unir 2 DataFrames con algunas columnas que se llamen igual y que esto lo reconozca, debemos utilizar pd.merge.
Además, si los DataFrames no tienen la misma cantidad de filas, rellena con NaN las vacías.
También podemos concatenar dataframes enteros con columna/s de otros dataframes. (en la imagen se ve el ejemplo). | VOLVER⤴️
abcdef = pd.concat([abcd,ef],axis=1)
abcdef.head()
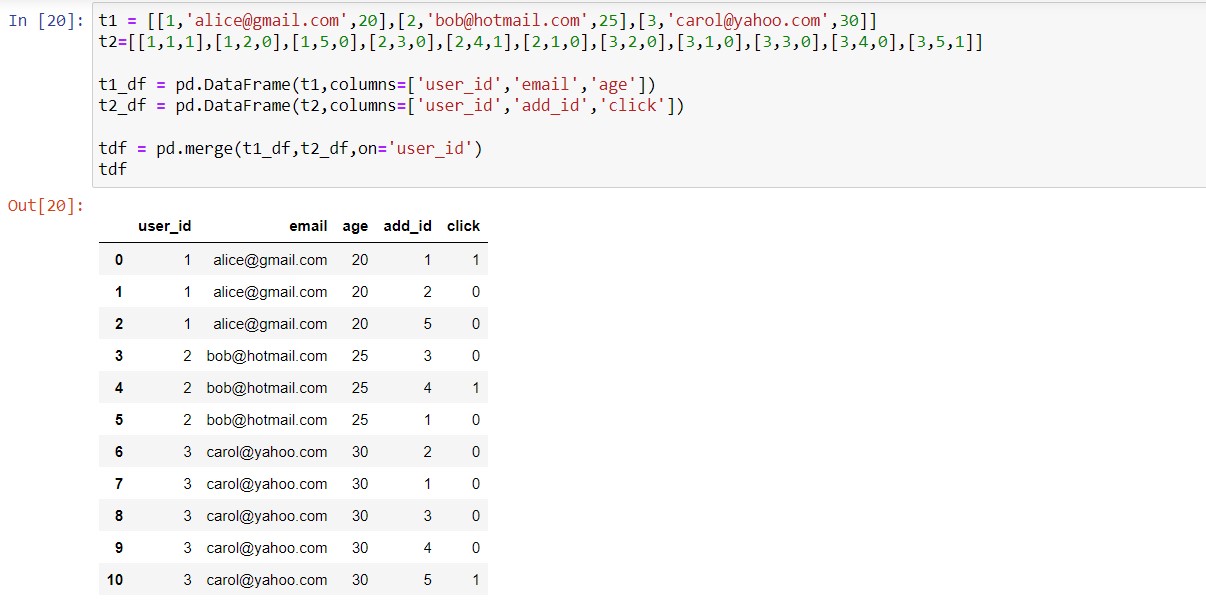
Hacer un merge de dataframes
pd.merge(df1,df2,...,dfn,on='col')]
Con este método podremos juntar 2 ó más dataframes que tengan 1 ó más columnas en común. Va a utilizar la columna on=‘col’ como fija, y va a copiar todo el resto de columnas una al lado de la otra, dejando la ‘col’ intacta. | VOLVER⤴️
t1 = [[1,'alice@gmail.com',20],[2,'bob@hotmail.com',25],[3,'carol@yahoo.com',30]]
t2=[[1,1,1],[1,2,0],[1,5,0],[2,3,0],[2,4,1],[2,1,0],[3,2,0],[3,1,0],[3,3,0],[3,4,0],[3,5,1]]
t1_df = pd.DataFrame(t1,columns=['user_id','email','age'])
t2_df = pd.DataFrame(t2,columns=['user_id','add_id','click'])
tdf = pd.merge(t1_df,t2_df,on='user_id')
tdf
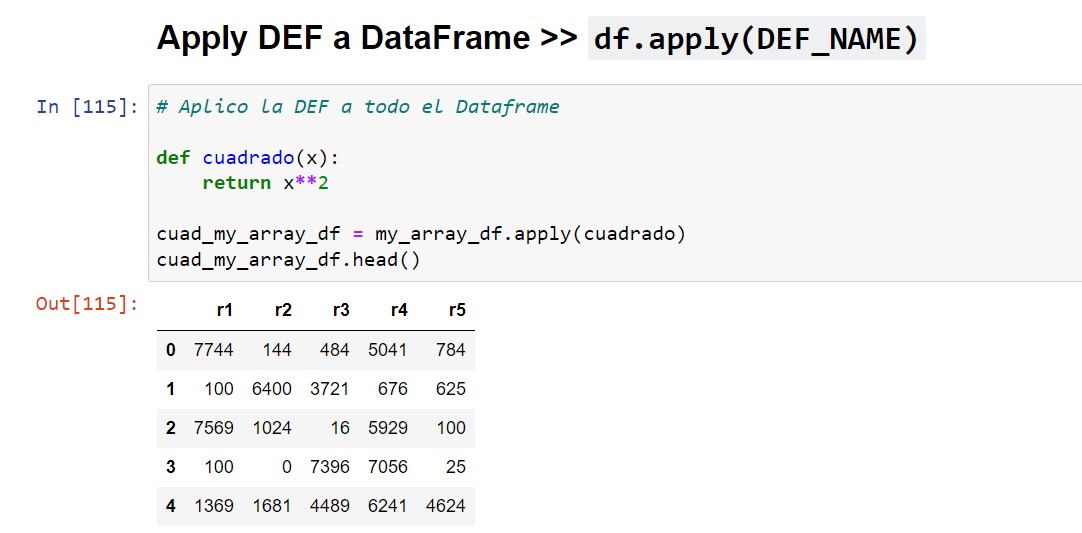
Correr función al dataframe
df.apply(DEF_NAME)
De esta manera podremos aplicar una función a todos los valores del dataframe. | VOLVER⤴️
ℹ️ Notemos como manejamos los resultados de la función al aplicársela al dataframe. En este caso definimos una nueva variable llamada cuad_my_array_df para sacar los resultados, lo cual nos generó un nuevo dataframe. Si sólo hubiésemos escrito el código sin definirle la variable, entonces sólo nos hubiese mostrado el resultado. En realidad no sólo nos muestra el resultado al no definirle variable, sino que crea un objeto del tipo pandas.core.frame.DataFrame y lo aloja en la memoria. De todas formas, no pisa el dataframe original.# Aplico la DEF a todo el Dataframe
def cuadrado(x):
return x**2
cuad_my_array_df = my_array_df.apply(cuadrado)
cuad_my_array_df.head()
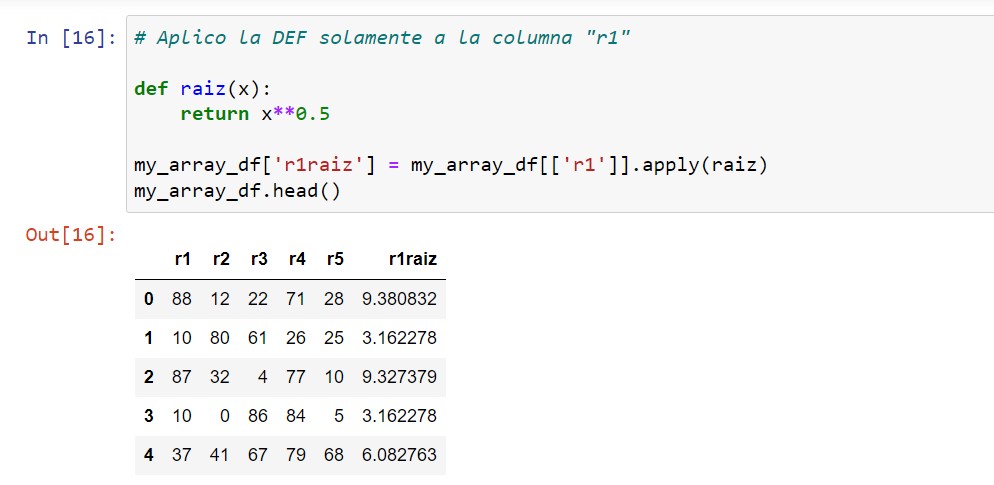
Correr función a una columna del dataframe
df['col'].apply(DEF_NAME)
De esta manera podremos aplicar una función a los valores de una columna en particular del dataframe. | VOLVER⤴️
# Aplico la DEF solamente a la columna "r1"
def raiz(x):
return x**0.5
my_array_df['r1raiz'] = my_array_df[['r1']].apply(raiz)
my_array_df.head()
Reemplazar columnas por filas y viceversa
df.transpose()
Con el método transpose() vamos a poder hacer un switch entre filas y columnas, vale decir, las columnas pasarán a ser filas, y las filas serán columnas. | VOLVER⤴️
my_array_df_tr = my_array_df.transpose()
my_array_df_tr

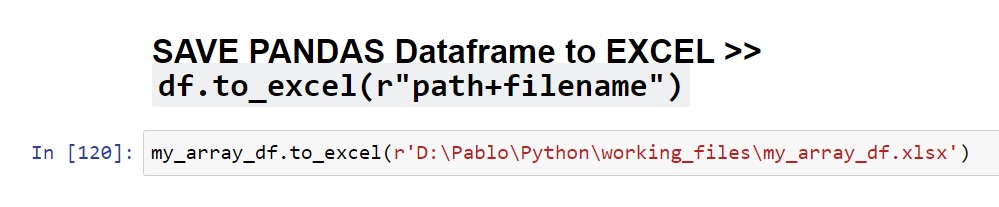
Guardar dataframe en hoja excel
df.to_excel(r'path+filename')
Si luego de finalizar el trabajo en pandas, deseáramos pasar el trabajo a una hoja excel 😭, con este método podremos hacerlo. | VOLVER⤴️
my_array_df.to_excel(r'D:\Pablo\Python\working_files\my_array_df.xlsx')
Haciendo un breve resumen de lo expuesto aquí, hemos visto varios métodos de pandas para el manejo de la información. A nuestro entender, son muy utilizados cuando estamos trabajando con datos de uno o varios pozos de petróleo y gas. Quedan cientos de métodos todavía sin explorar, los cuales seguramente iremos conociendo a medida que continuemos utilizando pandas para el log analysis.
Les agradecemos su tiempo y esperamos fervientemente que hayan disfrutado este artículo. Si tienen alguna consulta, desean hacer algún comentario o sugerencia para mejorar el contenido, o simplemente indicarles qué les pareció este artículo, debajo pueden hacerlo.
Esperamos reencontrarlos en algún otro artículo del sitio. Hasta luego!
Tags
Recent Posts