Emulación de curvas de pozo utilizando RNA - Entrenamiento y Aplicación del modelo con Keras - Parte 1
Uno de los usos más comunes que le dan los petrofísicos y analistas de perfiles a las redes neuronales, según nuestro entender, es la emulación de datos de interés para un pozo de petróleo o gas, a partir del entrenamiento de redes neuronales con datos registrados en ese mismo pozo, y/o en otros pozos cercanos donde las litologías atravesadas en todos ellos sean análogas (mismas formaciones, espesores similares, etc).
Bienvenidas/os!!, muchas gracias por visitarnos, si están comenzando en Python y este es el primer artículo al que entran en nuestro sitio, les recomendamos visitar Primeros Pasos.
ℹ️ Les recordamos que todos los ejemplos de códigos en nuestro sitio web van a encontrarlos en nuestro repositorio GitHub. Los códigos de este artículo los encontrarán en ANN_supervised_regression_train-apply.ipynb.
Cuando se trata de obtención de datos petrofísicos de pozos de petróleo y gas, hay varias fuentes, de las cuales nombraremos dos muy comunes:
- Los datos petrofísicos obtenidos mediante ensayos de laboratorio de muestras de roca y/o fluido adquiridas en los pozos.
- Los datos petrofísicos inferidos de registros de perfilaje de pozo.

Figura 1: A la izquierda, esquema de un perfilaje de pozo. A la derecha, foto de unas muestras de suelo en un laboratorio (Fuente imagen laboratorio: freepik.com)
Lamentablemente, lo usual es que estos datos no se repitan en todos los pozos, de hecho, la mayoría de las veces ni siquiera se repiten en pozos cercanos unos de otros. Los motivos de ello son variados, los costos de adquirir toda esa información siempre es una de las razones principales, pero también hay temas de tiempos, problemas de adquisición debidos a condiciones de pozo, fallas en los equipos, etc.
Ante este panorama, los petrofísicos y analistas de perfiles nos hemos visto obligados a tratar de encontrar maneras de calcular estos datos cuando no están presentes en uno o varios pozos. Dependiendo de la situación, del conocimiento y experiencia del petrofísico, etc, podemos recurrir a diferentes caminos para ello. La utilización de relaciones empíricas es un método usual, el entrenamiento y aplicación de Redes Neuronales Artificiales (RNA) es otro procedimiento muy común también.
En los siguientes 3 artículos examinaremos, paso a paso, desde la elección de las curvas que utilizaremos en la RNA, hasta el entrenamiento del modelo. (Debido a la extensión del código para realizar esto, nos vimos obligados a dividir esta tarea en 3 artículos).
Para comenzar, cargaremos los datos de todos los pozos, desde los archivos .las, con las librerías lasio y pandas, y determinaremos el número de veces que aparece cada curva en ellos con el fin de elegir las curvas adecuadas para entrenar la red. Todo esto lo repasaremos en este artículo.
A continuación, en el artículo Emulación de curvas de pozo utilizando RNA - Entrenamiento y Evaluación del modelo con Keras - Parte 2, elegiremos uno de los pozos como Pozo Entrenador e importaremos la información desde el archivo .las nuevamente con lasio y pandas. Luego haremos el control de calidad de estos datos. Acto seguido, visualizaremos un plot combinado de sus datos.
Una vez finalizada la depuración de los datos del Pozo Entrenador, en el artículo Emulación de curvas de pozo utilizando RNA - Entrenamiento y Evaluación del modelo con Keras - Parte 3 exploraremos el código para elegir el tramo y las curvas que intervendrán en el procesamiento. Y para finalizar, entrenaremos nuestro modelo con la librería Keras, crearemos una curva emulada utilizando dicho modelo, y la compararemos con la curva target en un plot.
Es bueno hacer la aclaración que este tipo de RNA es una Red Neuronal Artificial Supervisada para análisis de Regresión.
Sin más, comencemos:
POZOS DE TRABAJO
En esta parte, cargaremos los datos de todos los pozos de trabajo almacenados en archivos .las para determinar y seleccionar las curvas que utilizaremos en el entrenamiento de la red.
INDICE
- Importar Librerías
- Revisamos todos los archivos .LAS en la carpeta de trabajo
- Elegimos los archivos .LAS de trabajo
- Exportamos los archivos .LAS con lasio y pasamos cada .LAS a 1 DF pandas
- Chequeamos cantidad de pozos y cantidad de veces que aparece cada curva en los pozos
Importar Librerías
Como hemos visto en artículos anteriores, lo primero que haremos es importar todas las librerías que utilizaremos en el notebook.
import pandas as pd
import numpy as np
import lasio
from collections import Counter
import matplotlib.pyplot as plt
import mplcursors
%matplotlib inline
%matplotlib notebook
from matplotlib.ticker import MaxNLocator
from matplotlib.ticker import StrMethodFormatter
%load_ext tensorboard
import tensorflow as tf
import datetime
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping
from sklearn.preprocessing import StandardScaler
# from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
import fnmatch
import glob, os
from IPython.display import clear_output
import warnings
warnings.filterwarnings('ignore')
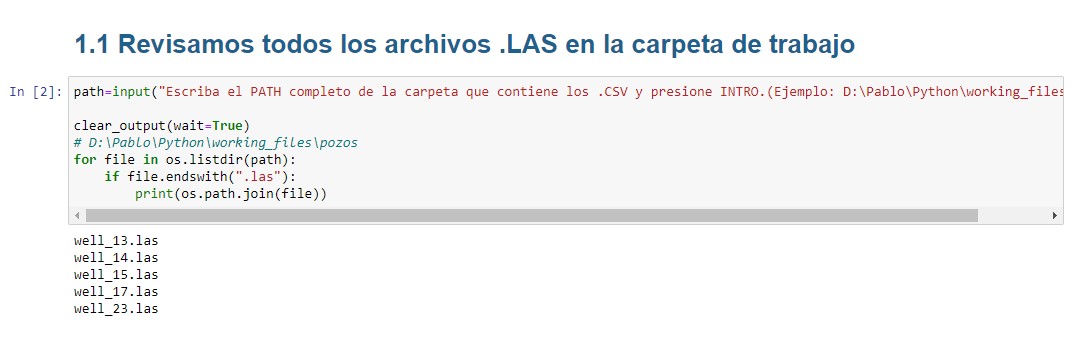
Revisamos todos los archivos .LAS en la carpeta de trabajo
Con el siguiente código vamos a setear la carpeta de trabajo creando una variable llamada path, la cual contendrá la ruta completa del directorio de trabajo en formato que lo pueda leer python (con doble barra invertida para separar los las carpetas), y también podremos visualizar todos los archivos .las presentes en dicha carpeta.
Al correr esta celda, nos pedirá un PATH. Ahí deberemos escribir la ruta completa de la carpeta de trabajo utilizando una sola barra invertida para separar carpetas de subcarpetas, luego debemos 👉presionar la tecla INTRO👈. (En el ejemplo escribimos D:\Pablo\Python\working_files\pozos).
⚠️ Todos los archivos deben estar dentro de una misma carpeta, ya que el siguiente código busca los archivos .las dentro de una única carpeta (no va a encontrar archivos .las si están en subcarpetas de esta carpeta).ℹ️ el path está comentado en el código. Esto es útil para copiarlo y pegarlo directamente cada vez que utilicemos el notebook.
path=input("Escriba el PATH completo de la carpeta que contiene los .CSV y presione INTRO.(Ejemplo: D:\Pablo\Python\working_files\pozos)")
clear_output(wait=True)
# D:\Pablo\Python\working_files\pozos
for file in os.listdir(path):
if file.endswith(".las"):
print(os.path.join(file))
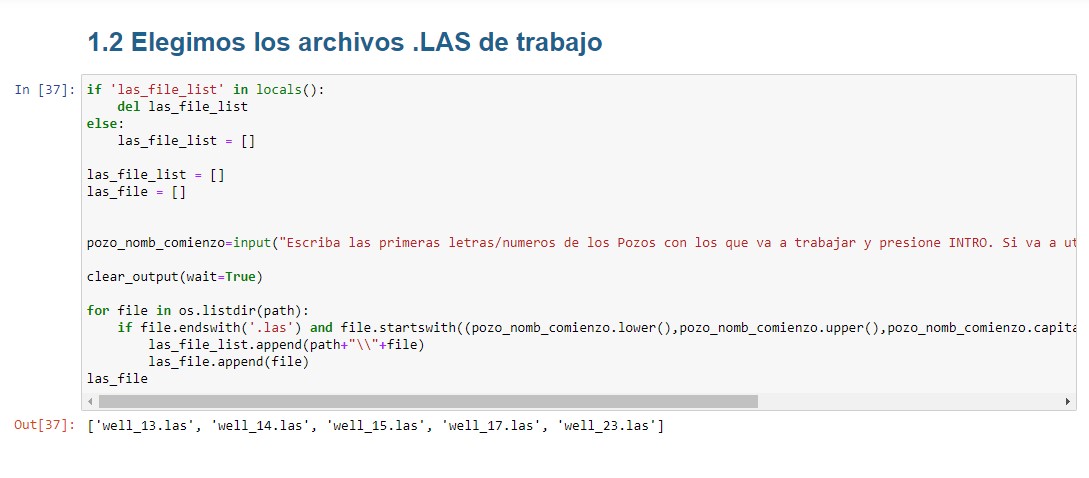
Elegimos los archivos .LAS de trabajo
Una vez que identificamos con cuáles pozos vamos a trabajar, utilizaremos la siguiente celda para seleccionarlos. Para ello, vamos a introducir los primeros caracteres del nombre de los archivos cuando nos lo pida la celda, luego debemos 👉presionar la tecla INTRO👈 (Si deseamos incluir TODOS los pozos de la carpeta, sólo deberemos presionar INTRO sin entrear ningún caracter).
⚠️ Si con este código no agregamos todos los archivos .las que deseamos a la lista, podemos volver a correr la celda utilizando otros caracteres. Cada vez que lo hagamos, vamos a incluir elementos a la lista. También podemos agregarlos manualmente utilizando append u otra opción de Listas en Python.
Esta celda va a crear dos listas:
- las_file_list: Cada elemento de esta lista es un string con la ruta completa de cada archivo .las que hayamos elegido al correr esta celda.(La vamos a usar para importar los .las con lasio)
- las_file: Cada elemento de esta lista es un string también, pero que se corresponde con cada nombre de los archivos .las elegido al correr la celda. (La vamos a utilizar para nombrar los dataframes pandas con el nombre del archivo .las del cual provienen, removiéndole los caracteres especiales si los tuviera).
if 'las_file_list' in locals():
del las_file_list
else:
las_file_list = []
las_file_list = []
las_file = []
pozo_nomb_comienzo=input("Escriba las primeras letras/numeros de los Pozos con los que va a trabajar y presione INTRO. Si va a utilizar todos los .LAS de la carpeta, solo presione INTRO")
clear_output(wait=True)
for file in os.listdir(path):
if file.endswith('.las') and file.startswith((pozo_nomb_comienzo.lower(),pozo_nomb_comienzo.upper(),pozo_nomb_comienzo.capitalize())):
las_file_list.append(path+"\\"+file)
las_file.append(file)
las_file
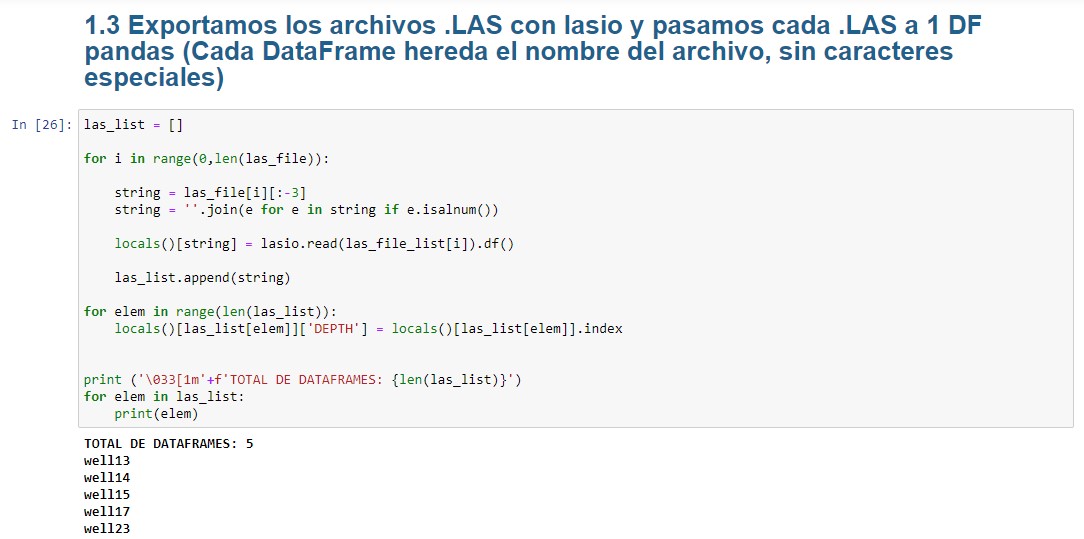
Exportamos los archivos .LAS con lasio y pasamos cada .LAS a 1 DF pandas (Cada DataFrame hereda el nombre del archivo, sin caracteres especiales)
En esta celda vamos a crear 1 df pandas por cada archivo .las elegido en la celda anterior. Utilizamos las_file_list para importar los archivos .las con lasio, que inmediatamente convertiremos a df panda.las_file lo usamos para crear la lista las_list, con la cual nombraremos cada df removiéndole caracteres especiales.
Además, crearemos en cada df la columna DEPTH a partir del index de cada archivo lasio.
las_list = []
for i in range(0,len(las_file)):
string = las_file[i][:-3]
string = ''.join(e for e in string if e.isalnum())
locals()[string] = lasio.read(las_file_list[i]).df()
las_list.append(string)
for elem in range(len(las_list)):
locals()[las_list[elem]]['DEPTH'] = locals()[las_list[elem]].index
print ('\033[1m'+f'TOTAL DE DATAFRAMES: {len(las_list)}')
for elem in las_list:
print(elem)
Chequeamos cantidad de pozos y cantidad de veces que aparece cada curva en los pozos
Para finalizar con esta primera parte, generaremos una lista llamada curves_list, donde cada elemento va a ser el nombre de cada curva de todos los dataframes pandas recientemente creados. Luego contaremos los nombres repetidos y los visualizaremos.
print(f'NUMERO DE POZOS:{len(las_list)}')
print(*las_list,sep=', ')
print('\n')
print('NOMBRE DE LA CURVA,','CANTIDAD DE POZOS DONDE APARECE:')
curves_list = []
# hago un merge de todas las curvas en una sola LIST
for i in range(len(las_list)):
curves_list = curves_list + (list(locals()[las_list[(i)]].columns))
# ordeno alfabeticamente la LIST de curvas y luego encuentro las curvas más comunes en la LIST
curves_list.sort()
dict_curves = dict(Counter(curves_list).most_common())
Counter(curves_list).most_common()
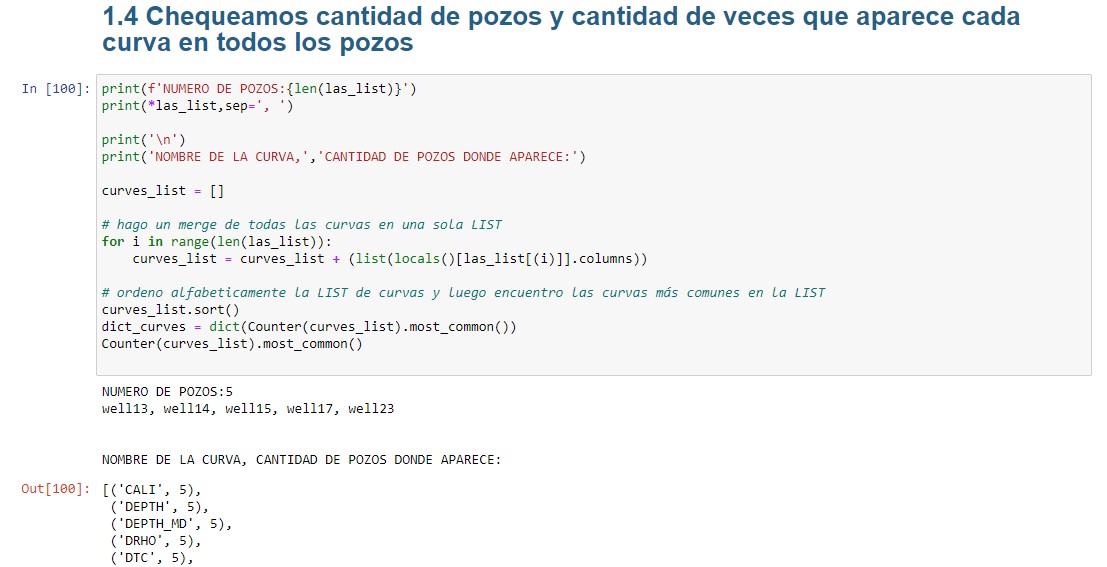
Resumiendo, hemos cargado datos de pozos almacenados en archivos .las contenidos en una misma carpeta. Luego verificamos su contenido y chequeamos la cantidad de veces que aparece cada curva en dichos pozos.
Con esto terminamos la primera parte de nuestra tarea. En el artículo Emulación de curvas de pozo utilizando RNA - Entrenamiento y Evaluación del modelo con Keras - Parte 2 continuaremos con la segunda parte: carga y QC de los datos del Pozo Entrenador.
Les agradecemos su tiempo y esperamos fervientemente que hayan disfrutado este artículo. Si tienen alguna consulta, desean hacer algún comentario o sugerencia para mejorar el contenido, o simplemente indicarles qué les pareció este artículo, debajo pueden hacerlo.
Es nuestro mayor deseo reencontrarlos en algún otro artículo del sitio. Hasta luego!
Tags
Recent Posts