Importar, manejar y graficar datos de archivos .CSV en Python

Esta vez, vamos a seguir los pasos para cargar uno o más archivos con la extensión .csv (separados por comas) almacenados en una misma carpeta, hacer un control de calidad de los datos utilizando pandas, y por último, graficarlos con seaborn.
Bienvenidas/os!!, muchas gracias por visitarnos, si están comenzando en Python y este es el primer artículo al que entran en nuestro sitio, les recomendamos visitar Primeros Pasos.
ℹ️ Recuerden que todos los ejemplos de códigos en nuestro sitio web van a encontrarlos en nuestro repositorio GitHub. Los códigos de este artículo los encontrarán en csv_pandas_sns.ipynb.
En este artículo utilizaremos la librería scipy para filtrar una curva cualquiera almacenada en un dataframe que previamente crearemos.
CARGA DE LOS DATOS
La carga/importación la haremos utilizando algo de código python y pandas.
Importamos TODAS las librerías necesarias para cargar, manejar y visualizar los datos:
ℹ️ Es aconsejable importar todas las librerías que vayamos necesitando a lo largo de todo el notebook en una misma celda al comienzo del mismo, y no tener líneas con import en varias celdas.import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
from IPython.display import clear_output>
import warnings
warnings.filterwarnings('ignore')
Ahora vamos a ver los nombres de los archivos .csv en una carpeta. Si corremos la celda con el siguente código, nos pedirá un PATH. Ahí deberemos escribir la ruta o “path” completa, luego debemos 👉presionar la tecla INTRO👈. En el ejemplo escribimos D:\Pablo\Python\working_files.
ℹ️ El path está comentado en el código, así lo copiamos y pegamos directamente cuando nos lo pida.path=input("Escriba el PATH completo de la carpeta que contiene los .CSV y presione INTRO. Ejemplo: D:\Pablo\Python\working_files")
clear_output(wait=True)
# D:\Pablo\Python\working_files
for file in os.listdir(path):
if file.endswith(".csv"):
print(os.path.join(file))
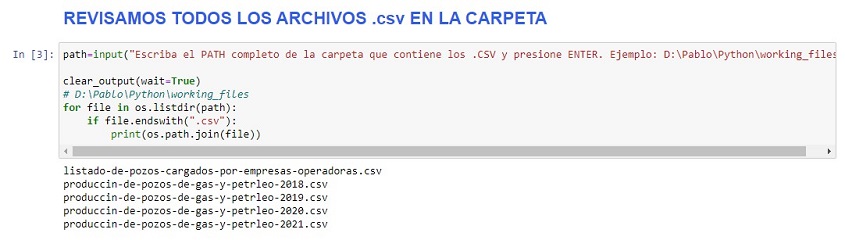
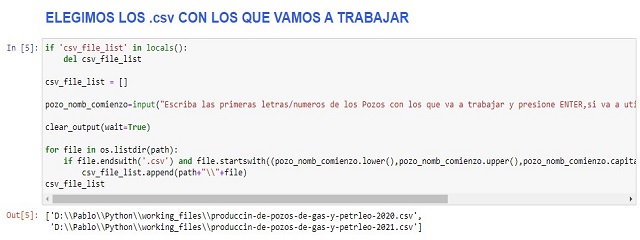
Una vez que podemos verlos, vamos a utilizar la siguiente celda para elegir cuales queremos. Para ello, vamos a introducir los primeros caracteres del nombre de los archivos cuando nos lo pida la celda, luego 👉presionar la tecla INTRO👈 (en el ejemplo, escribimos produccin-de-pozos-de-gas-y-petrleo-202).
⚠️ Si con este código no agregamos todos los archivos .las que deseamos a la lista, podemos volver a correr la celda utilizando otros caracteres. Cada vez que lo hagamos, vamos a incluir elementos a la lista. También podemos agregarlos manualmente utilizando append u otra opción de Listas en Python.
if 'csv_file_list' in locals():
del csv_file_list
csv_file_list = []
pozo_nomb_comienzo=input("Escriba las primeras letras/numeros de los Pozos con los que va a trabajar y presione INTRO,si va a utilizar todos los .CSV de la carpeta, solo presione INTRO")
clear_output(wait=True)
for file in os.listdir(path):
if file.endswith('.csv') and file.startswith((pozo_nomb_comienzo.lower(),pozo_nomb_comienzo.upper(),pozo_nomb_comienzo.capitalize())):
csv_file_list.append(path+"\\"+file)
csv_file_list
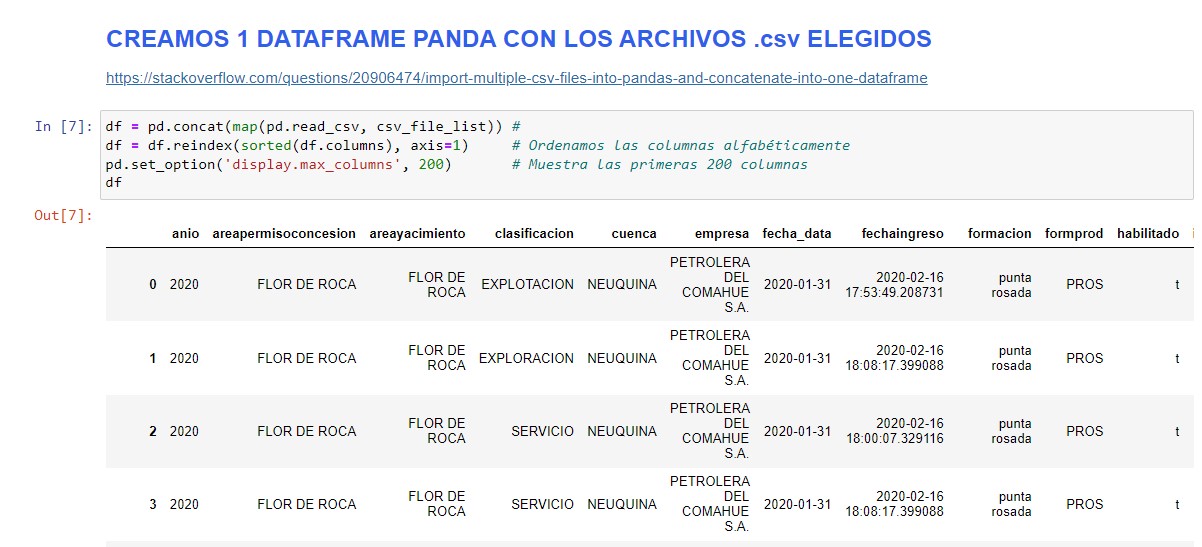
MANEJO DE LOS DATOS CON PANDAS
El siguiente paso es ver y hacer un control de calidad de los datos, para eso crearemos un archivo del tipo pandas dataframe, el cual nos va a servir para utilizar todo el potencial de pandas.
Creación del dataframe df:
df = pd.concat(map(pd.read_csv, csv_file_list))
df = df.reindex(sorted(df.columns), axis=1) # Ordenamos las columnas alfabéticamente
pd.set_option('display.max_columns', 200) # Nos muestra las primeras 200 columnas
df
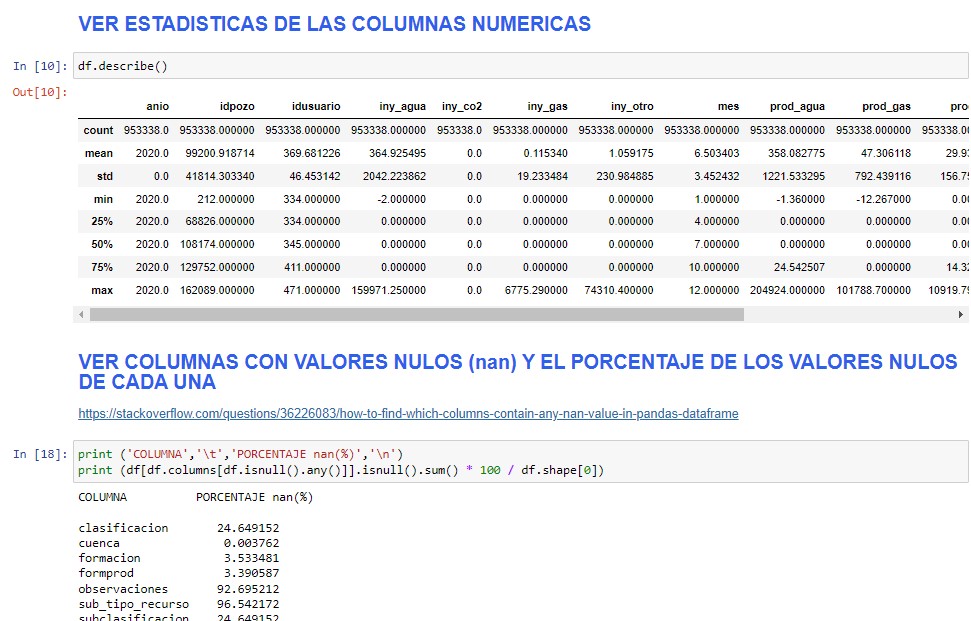
pandas es una herramienta muy poderosa para manejar datos, es muy sencillo filtar, obtener estadísticas, etc. En el archivo csv_pandas_sns.ipynb en nuestro repositorio GitHub vamos a encontrar muchos tips al respecto. Aquí sólo mostraremos un par de ejemplos en la imagen de abajo.
VISUALIZACIÓN GRÁFICA DE LOS DATOS CON SEABORN
Ahora llegó la hora más entretenida, ver gráficamente los datos. En este caso elegimos seaborn por su versatilidad, y porque es muy conveniente a la hora de trabajar con archivos de gran tamaño. (Recordemos que nuestro df tiene 1914005 filas y 38 columnas).
Vamos ver un par de ejemplos solamente en esta página. Si desean ver más por favor chequeen el archivo csv_pandas_sns .ipynb en nuestro repositorio GitHub, o en la página web de seaborn https://seaborn.pydata.org/.
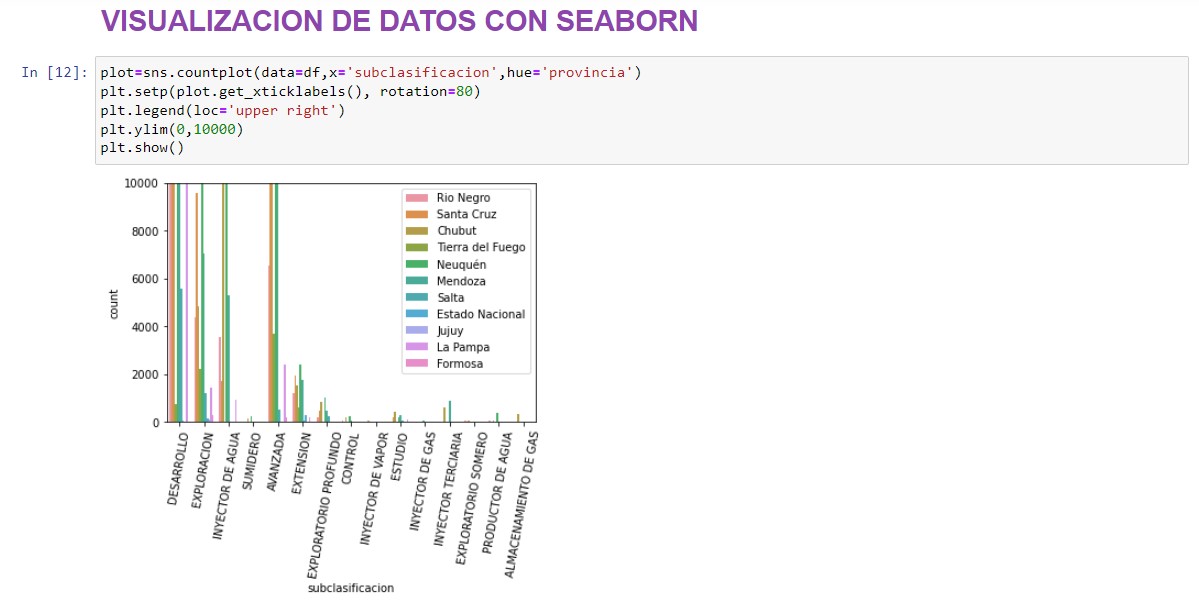
plot=sns.countplot(data=df,x='subclasificacion',hue='provincia')
plt.setp(plot.get_xticklabels(), rotation=80)
plt.legend(loc='upper right')
plt.ylim(0,10000)
plt.show()
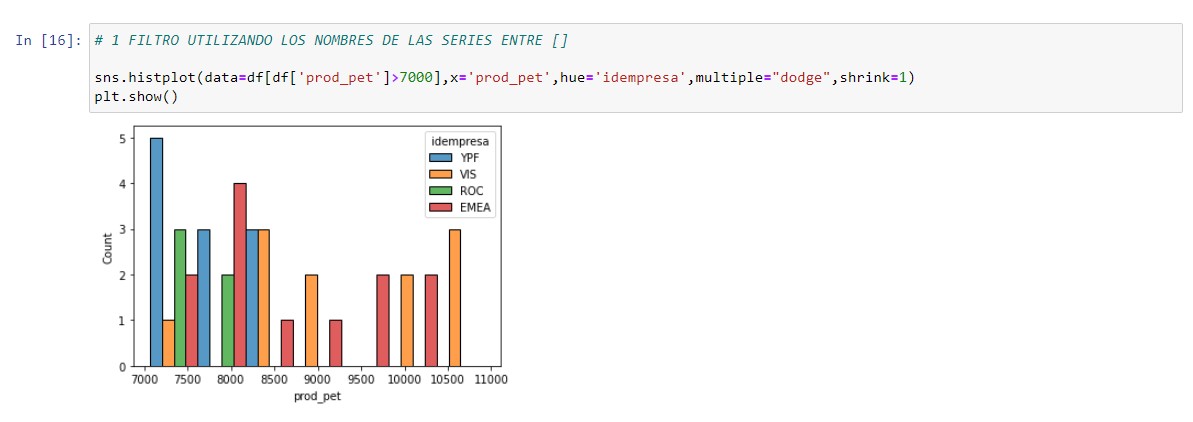
# 1 FILTRO UTILIZANDO LOS NOMBRES DE LAS SERIES ENTRE []
sns.histplot(data=df[df['prod_pet']>7000],x='prod_pet',hue='idempresa',multiple="dodge",shrink=1)
plt.show()
Recapitulando, hemos cargado varios archivos .csv y hemos incluido esa información en un solo pandas dataframe. A partir de allí, llevamos a cabo un control de calidad de la misma utilizando las herramientas de pandas. Por último, construimos algunos gráficos utilizando seaborn.
Les agradecemos su tiempo y esperamos fervientemente que hayan disfrutado este artículo. Si tienen alguna consulta, desean hacer algún comentario o sugerencia para mejorar el contenido, o simplemente indicarles qué les pareció este artículo, debajo pueden hacerlo.
Esperamos reencontrarlos en algún otro artículo del sitio. Hasta luego!
Tags
Recent Posts